LLM on openshift
我们继续之前的openshift集群安装, install doc, we have 2 node, 1 master, 1 worker.
接下来,我们在ocp上面部署大模型相关的应用,探索openshift AI的能力。
视频讲解:

gpu operator
首先要安装gpu operator,这个东西类似操作系统里面的显卡驱动,原理是通过operator带出来的deamon set,在每个有显卡的主机上,编译出来对应的内核驱动,并加载。
- https://docs.nvidia.com/datacenter/cloud-native/openshift/latest/introduction.html#openshift-introduction
要安装gpu operator,需要先安装一个节点特征发现器,就是发现节点特殊硬件的deamon set。 Installing the Node Feature Discovery (NFD) Operator
然后,我们就可以安装 gpu operator了,不安装NFD,gpu operator不工作。install gpu operator through opeartor hub
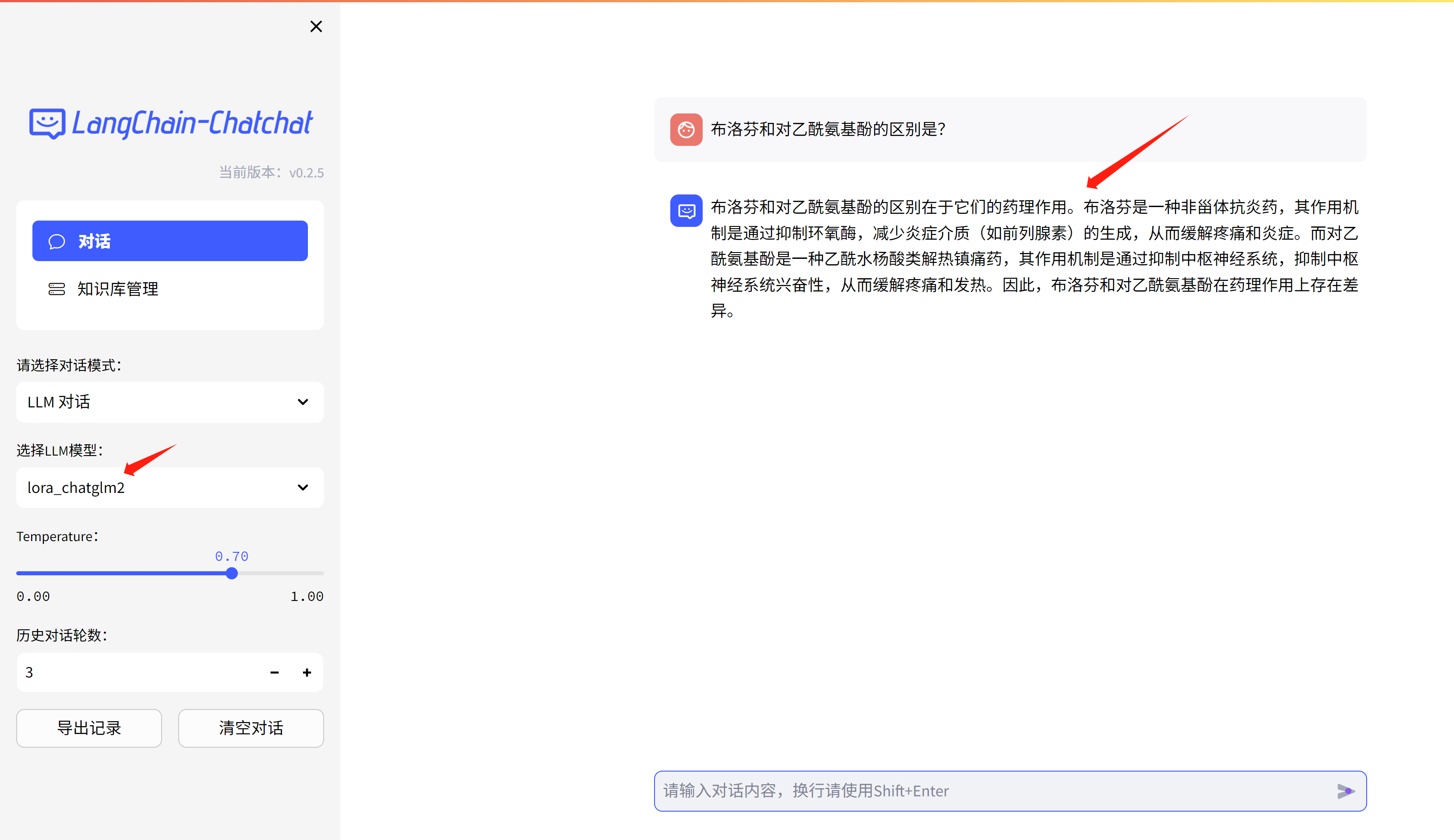
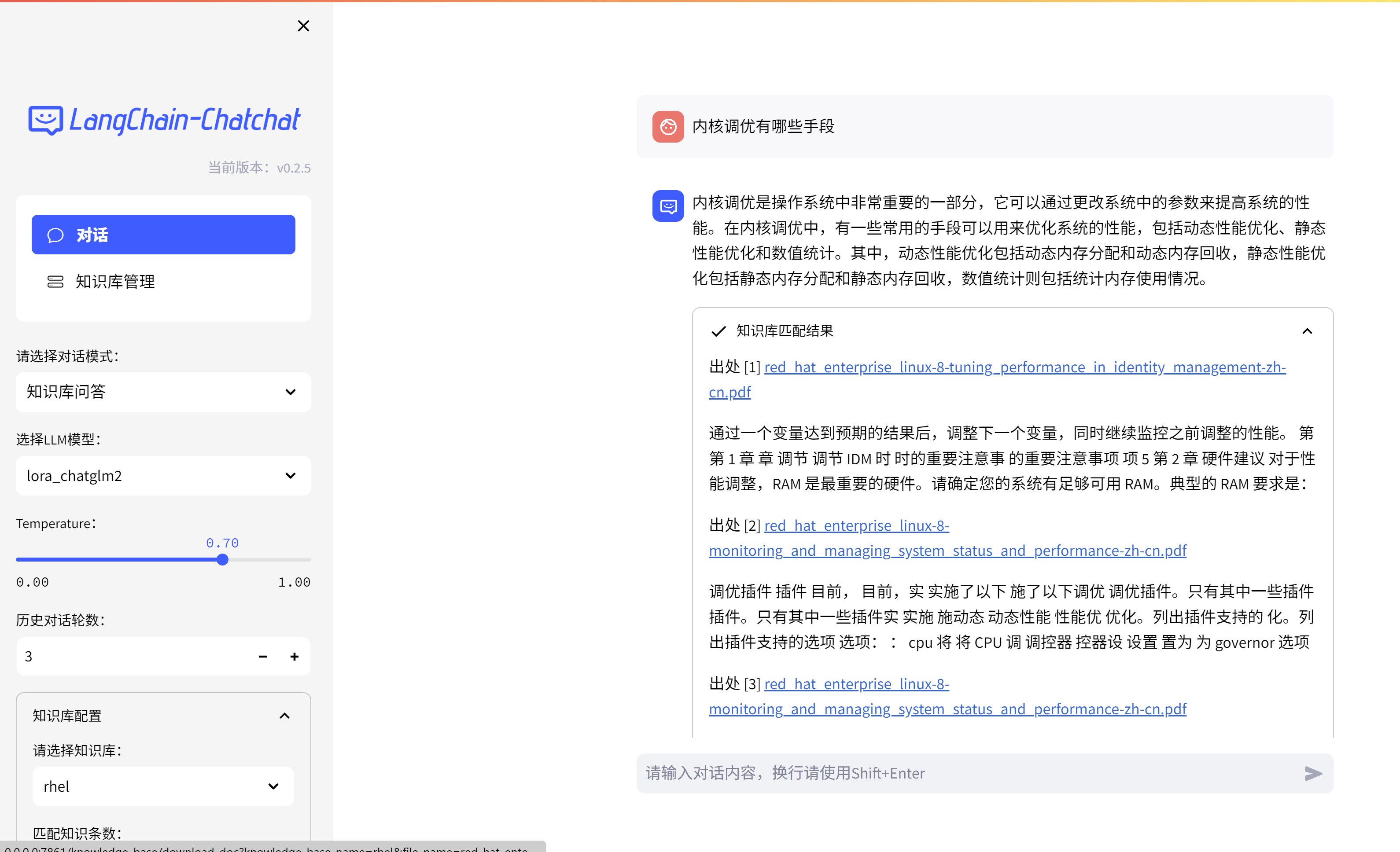
llm chat with a single pod
we will use docker.io/nvidia/cuda:12.2.2-devel-ubi9 to start container directly
我们在这里展示一下使用pod的方式,运行llm相关应用。我们会在nvidia提供的官方基础镜像上,直接运行,然后登录到pod内部,做和rhel上面相同的操作,而不是封装一个超级容器出来,自动运行一切。这么做的主要原因是,我们是展示ocp上运行pod的能力,而不是在这一步展示ocp的整合能力,为了方便省事,就不做封装容器这一步了。
start llm chat pod
我们直接用nvidia基座镜像运行pod,在pod里面用脚本进行相关部署和运行。
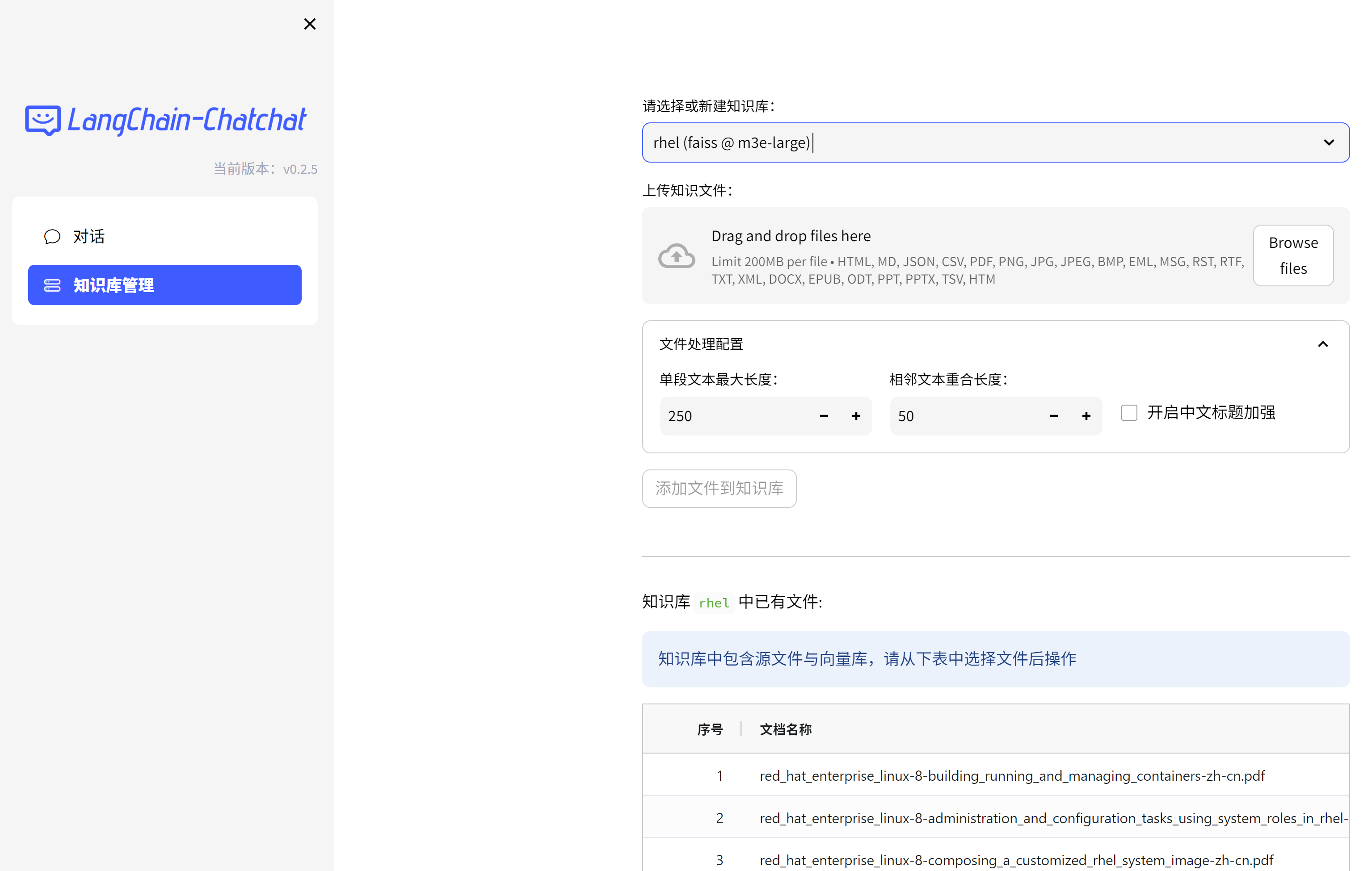
ocp storage setup
我们先准备一些静态的存储目录,这样pod就可以固定的访问相关的目录,不用担心pod重启,存储丢失。
# create some static host path to use
# go to worker-01-demo
# 01,02,03,04,05,06,07,08,09,10
for i in $(seq -w 1 20); do
mkdir -p "/var/wzh-local-pv/static/$i"
done
mkdir -p /var/wzh-local-pv/dynamic
chcon -Rt container_file_t /var/wzh-local-pv/
# delete content
for i in 13 14 17; do
rm -rf /var/wzh-local-pv/static/$i/*
done
# on helper
cat << EOF > ${BASE_DIR}/data/install/local-sc.yaml
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-volume
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
EOF
oc create --save-config -f ${BASE_DIR}/data/install/local-sc.yaml
cat << EOF > ${BASE_DIR}/data/install/local-pv.yaml
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv-01
spec:
capacity:
storage: 4500Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-volume
local:
path: /var/wzh-local-pv/static/01
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- worker-01-demo
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: local-pvc-demo
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 4500Gi
storageClassName: local-volume
EOF
oc create --save-config -n llm-demo -f ${BASE_DIR}/data/install/local-pv.yaml
# oc delete -n llm-demo -f ${BASE_DIR}/data/install/local-pv.yaml
# for all diretory, create them
var_i=0
for var_i in $(seq -w 1 20); do
oc create --save-config -n llm-demo -f - << EOF
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv-${var_i}
labels:
local-dir: local-dir-${var_i}
spec:
capacity:
storage: 4500Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-volume
local:
path: /var/wzh-local-pv/static/${var_i}
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- worker-01-demo
EOF
done
for var_i in $(seq -w 1 10); do
oc create --save-config -n llm-demo -f - << EOF
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: local-pvc-${var_i}
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 4500Gi
storageClassName: local-volume
selector:
matchLabels:
local-dir: local-dir-${var_i}
EOF
done
# then delete
var_i=0
for var_i in $(seq -w 1 10); do
oc delete -n llm-demo -f - << EOF
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: local-pvc-${var_i}
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 4500Gi
storageClassName: local-volume
EOF
done
var_i=0
for var_i in $(seq -w 1 10); do
oc delete -n llm-demo -f - << EOF
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv-${var_i}
spec:
capacity:
storage: 4500Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-volume
local:
path: /var/wzh-local-pv/static/${var_i}
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- worker-01-demo
EOF
donestart pod
我们启动一个pod,暴露tcp服务,然后在这个pod里面,安装和运行LLM
# https://master.sdk.operatorframework.io/docs/best-practices/pod-security-standards/
oc create ns llm-demo
oc label --overwrite ns llm-demo \
pod-security.kubernetes.io/enforce=privileged
cat << EOF > ${BASE_DIR}/data/install/pod.yaml
---
apiVersion: v1
kind: Service
metadata:
name: demo1
labels:
app: llm-demo
spec:
type: ClusterIP
selector:
app: llm-demo
ports:
- name: webui
protocol: TCP
port: 8501
targetPort: 8501
---
kind: Route
apiVersion: route.openshift.io/v1
metadata:
name: demo
labels:
app: llm-demo
spec:
to:
kind: Service
name: demo1
port:
targetPort: 8501
---
kind: Pod
apiVersion: v1
metadata:
annotations:
openshift.io/scc: privileged
name: demo1
labels:
app: llm-demo
spec:
nodeSelector:
kubernetes.io/hostname: worker-01-demo
restartPolicy: Always
containers:
- name: demo1
image: >-
docker.io/nvidia/cuda:12.2.2-devel-ubi9
# quaylab.infra.wzhlab.top:5443/wangzheng422/qimgs:gpu-nv-base-rhel92-v01
# docker.io/nvidia/cuda:12.2.2-cudnn8-devel-ubi9
securityContext:
# privileged: true
AllowPrivilegedContainer: true
env:
- name: key
value: value
command:
- sleep
- infinity
volumeMounts:
- mountPath: /data
name: demo
readOnly: false
resources:
limits:
nvidia.com/gpu: 2
volumes:
- name: demo
persistentVolumeClaim:
claimName: local-pvc-demo
EOF
oc create --save-config -n llm-demo -f ${BASE_DIR}/data/install/pod.yaml
# oc delete -n llm-demo -f ${BASE_DIR}/data/install/pod.yaml
# oc project llm-demo
oc rsh -n llm-demo demo1
dnf install -y wget vim git iproute iputils
dnf install -y https://mirror.stream.centos.org/9-stream/AppStream/x86_64/os/Packages/lftp-4.9.2-4.el9.x86_64.rpm
# https://docs.conda.io/projects/miniconda/en/latest/
mkdir -p /data/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /data/miniconda3/miniconda.sh
bash /data/miniconda3/miniconda.sh -b -u -p /data/miniconda3
# rm -rf ~/miniconda3/miniconda.sh
/data/miniconda3/bin/conda init bash
mkdir -p /data/py_env
conda create -p /data/py_env/chatchat --yes python=3.10
conda activate /data/py_env/chatchat
# conda deactivate
mkdir -p /data/git_env
cd /data/git_env
git clone --single-branch -b master https://github.com/chatchat-space/Langchain-Chatchat
cd Langchain-Chatchat
# edit requirements.txt
# comment out line with 'win32'
export ENV_CWD="/data/git_env/Langchain-Chatchat"
cd ${ENV_CWD}
pip install -r requirements.txt
# conda install --yes --file requirements.txt -c pytorch -c nvidia
mkdir -p /data/huggingface/
cd /data/huggingface
lftp http://172.21.6.98:11880
mirror chatglm2-6b
mirror m3e-large
get knowledge_base.tgz
cd ${ENV_CWD}/configs
/bin/cp -f model_config.py.example model_config.py
/bin/cp -f server_config.py.example server_config.py
/bin/cp -f kb_config.py.exmaple kb_config.py
/bin/cp -f basic_config.py.example basic_config.py
/bin/cp -f prompt_config.py.example prompt_config.py
# edit content of model_config.chatglm2.py
# vim disable auto indent => :set paste
/bin/cp -f model_config.chatglm2.py model_config.py
# no proxy to run ...
unset http_proxy
unset https_proxy
unset no_proxy
cd ${ENV_CWD}
python startup.py -a
finetune with a single pod
we will create a single pod with 2 container, 1 for finetune, 1 for llm-chat
create container image
podman run -it --rm docker.io/nvidia/cuda:12.2.2-devel-ubi9 bash
# remount podman dir
# https://github.com/containers/podman/issues/2396
mkfs.xfs /dev/vdb
mount /dev/vdb /mnt
mkdir -p /mnt/{containers,tmp}
mount -o bind /mnt/containers /var/lib/containers
mount -o bind /mnt/tmp /var/tmp
restorecon -v /var/lib/containers/
restorecon -v /var/tmp
# [Conda Environments with Docker](https://medium.com/@chadlagore/conda-environments-with-docker-82cdc9d25754)
##################
## for llm chatchat
mkdir -p /data/nv
cd /data/nv
cat << 'EOF' > nv.Dockerfile
FROM docker.io/nvidia/cuda:12.2.2-devel-ubi9
RUN dnf install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpm && \
/usr/bin/crb enable && \
dnf install -y wget vim git iproute iputils conda && \
dnf install -y https://mirror.stream.centos.org/9-stream/AppStream/x86_64/os/Packages/lftp-4.9.2-4.el9.x86_64.rpm && \
dnf clean all && \
conda init bash
######################
# for chatchat
RUN mkdir -p /data/py_env && \
conda create -p /data/py_env/chatchat --yes python=3.10
RUN echo "conda activate /data/py_env/chatchat" >> ~/.bashrc
ENV PATH /data/py_env/chatchat/bin:$PATH
RUN mkdir -p /data/git_env && \
cd /data/git_env && \
git clone --single-branch -b master https://github.com/chatchat-space/Langchain-Chatchat && \
cd Langchain-Chatchat && \
pip install -r requirements.txt
RUN /bin/rm -rf ~/.cache
EOF
podman build --squash -t quay.io/wangzheng422/qimgs:llm-chatchat-cuda-12.2.2-devel-ubi9-v01 -f nv.Dockerfile ./
podman push quay.io/wangzheng422/qimgs:llm-chatchat-cuda-12.2.2-devel-ubi9-v01
###################
## for llm-factory
mkdir -p /data/nv01
cd /data/nv01
cat << 'EOF' > nv.Dockerfile
FROM docker.io/nvidia/cuda:12.2.2-devel-ubi9
RUN dnf install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpm && \
/usr/bin/crb enable && \
dnf install -y wget vim git iproute iputils conda && \
dnf install -y https://mirror.stream.centos.org/9-stream/AppStream/x86_64/os/Packages/lftp-4.9.2-4.el9.x86_64.rpm && \
dnf clean all && \
conda init bash
######################
# for llama-factory
RUN mkdir -p /data/py_env && \
conda create -p /data/py_env/llama_factory --yes python=3.10
RUN echo "conda activate /data/py_env/llama_factory" >> ~/.bashrc
ENV PATH /data/py_env/llama_factory/bin:$PATH
RUN mkdir -p /data/git_env && \
cd /data/git_env && \
git clone --single-branch -b main https://github.com/hiyouga/LLaMA-Factory && \
cd LLaMA-Factory && \
pip install -r requirements.txt && \
pip install flash-attn
RUN /bin/rm -rf ~/.cache
EOF
podman build --squash -t quay.io/wangzheng422/qimgs:llm-factory-cuda-12.2.2-devel-ubi9-v01 -f nv.Dockerfile ./
podman push quay.io/wangzheng422/qimgs:llm-factory-cuda-12.2.2-devel-ubi9-v01
################
# for huggingface chatglm2-6b
mkdir -p /data/nv
cd /data/nv
cat << 'EOF' > nv.Dockerfile
FROM registry.access.redhat.com/ubi9/ubi:9.2
RUN dnf install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpm && \
dnf install -y conda && \
dnf clean all && \
conda init bash
RUN mkdir -p /data/py_env && \
conda create -p /data/py_env/hg_cli --yes python=3.10
RUN echo "conda activate /data/py_env/hg_cli" >> ~/.bashrc
ENV PATH /data/py_env/hg_cli/bin:$PATH
RUN pip install --upgrade huggingface_hub && \
mkdir -p /data/huggingface/chatglm2-6b/ && \
huggingface-cli download THUDM/chatglm2-6b --repo-type model --revision main --local-dir /data/huggingface/chatglm2-6b/ --local-dir-use-symlinks False --resume-download
RUN /bin/rm -rf ~/.cache
EOF
podman build --squash -t quay.io/wangzheng422/qimgs:llm-chatglm2-6b -f nv.Dockerfile ./
podman push quay.io/wangzheng422/qimgs:llm-chatglm2-6b
################
# for huggingface m3e-large
mkdir -p /data/nv
cd /data/nv
cat << 'EOF' > nv.Dockerfile
FROM registry.access.redhat.com/ubi9/ubi:9.2
RUN dnf install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpm && \
dnf install -y conda && \
dnf clean all && \
conda init bash
RUN mkdir -p /data/py_env && \
conda create -p /data/py_env/hg_cli --yes python=3.10
RUN echo "conda activate /data/py_env/hg_cli" >> ~/.bashrc
ENV PATH /data/py_env/hg_cli/bin:$PATH
RUN pip install --upgrade huggingface_hub && \
mkdir -p /data/huggingface/m3e-large/ && \
huggingface-cli download moka-ai/m3e-large --repo-type model --revision main --local-dir /data/huggingface/m3e-large/ --local-dir-use-symlinks False --resume-download
RUN /bin/rm -rf ~/.cache
EOF
podman build --squash -t quay.io/wangzheng422/qimgs:llm-m3e-large -f nv.Dockerfile ./
podman push quay.io/wangzheng422/qimgs:llm-m3e-large
start pod with finetune and chat container
cat << EOF > ${BASE_DIR}/data/install/pod.yaml
---
apiVersion: v1
kind: Service
metadata:
name: llm-finetune
labels:
app: llm-finetune-demo
spec:
type: ClusterIP
selector:
app: llm-finetune-demo
ports:
- name: chat-webui
protocol: TCP
port: 8501
targetPort: 8501
- name: factory-ui
protocol: TCP
port: 7860
targetPort: 7860
- name: factory-api
protocol: TCP
port: 8000
targetPort: 8000
---
kind: Route
apiVersion: route.openshift.io/v1
metadata:
name: llm-finetune-chatchat
labels:
app: llm-finetune-demo
spec:
to:
kind: Service
name: llm-finetune
port:
targetPort: 8501
---
kind: Route
apiVersion: route.openshift.io/v1
metadata:
name: llm-finetune-factory
labels:
app: llm-finetune-demo
spec:
to:
kind: Service
name: llm-finetune
port:
targetPort: 7860
---
kind: Pod
apiVersion: v1
metadata:
annotations:
openshift.io/scc: privileged
name: demo1
labels:
app: llm-finetune-demo
spec:
nodeSelector:
kubernetes.io/hostname: worker-01-demo
restartPolicy: Always
containers:
- name: chatchat
image: >-
docker.io/nvidia/cuda:12.2.2-devel-ubi9
# quaylab.infra.wzhlab.top:5443/wangzheng422/qimgs:gpu-nv-base-rhel92-v01
# docker.io/nvidia/cuda:12.2.2-cudnn8-devel-ubi9
securityContext:
# privileged: true
AllowPrivilegedContainer: true
env:
- name: key
value: value
command:
- sleep
- infinity
volumeMounts:
- mountPath: /data
name: demo
readOnly: false
resources:
limits:
nvidia.com/gpu: 2
- name: llama-factory
image: >-
docker.io/nvidia/cuda:12.2.2-devel-ubi9
# quaylab.infra.wzhlab.top:5443/wangzheng422/qimgs:gpu-nv-base-rhel92-v01
# docker.io/nvidia/cuda:12.2.2-cudnn8-devel-ubi9
securityContext:
# privileged: true
AllowPrivilegedContainer: true
env:
- name: key
value: value
command:
- sleep
- infinity
volumeMounts:
- mountPath: /data
name: demo
readOnly: false
resources:
limits:
nvidia.com/gpu: 2
volumes:
- name: demo
persistentVolumeClaim:
claimName: local-pvc-demo
EOF
oc create --save-config -n llm-demo -f ${BASE_DIR}/data/install/pod.yaml
# oc delete -n llm-demo -f ${BASE_DIR}/data/install/pod.yaml
##########################
# for factory
oc rsh -n llm-demo -c llama-factory demo1
bash /data/miniconda3/miniconda.sh -b -u -p /data/miniconda3
/data/miniconda3/bin/conda init bash
mkdir -p /data/py_env
conda create --yes -p /data/py_env/llama_factory python=3.10
conda activate /data/py_env/llama_factory
# conda deactivate
mkdir -p /data/git_env
cd /data/git_env
git clone --single-branch -b main https://github.com/hiyouga/LLaMA-Factory
cd /data/git_env/LLaMA-Factory
pip install -r requirements.txt
unset http_proxy
unset https_proxy
unset no_proxy
unset PROXY
cd /data/git_env/LLaMA-Factory
CUDA_VISIBLE_DEVICES=0 python src/train_web.py
# http://llm-finetune-factory-llm-demo.apps.demo-gpu.wzhlab.top/
# finetuen for data oaast_sft_zh.json
# for supervised fine-tune
# start llm api
cd /data/git_env/LLaMA-Factory
python src/api_demo.py \
--model_name_or_path /data/huggingface/chatglm2-6b \
--template chatglm2 \
--finetuning_type lora \
--checkpoint_dir /data/git_env/LLaMA-Factory/saves/ChatGLM2-6B-Chat/lora/2023-10-27-08-14-02
##########################
# for llm-chat
oc rsh -n llm-demo -c chatchat demo1
bash /data/miniconda3/miniconda.sh -b -u -p /data/miniconda3
/data/miniconda3/bin/conda init bash
conda activate /data/py_env/chatchat
# conda deactivate
# test connect to llm api
curl http://llm-finetune:8000
export ENV_CWD="/data/git_env/Langchain-Chatchat"
cd ${ENV_CWD}/configs
/bin/cp -f model_config.py.example model_config.py
/bin/cp -f server_config.py.example server_config.py
/bin/cp -f kb_config.py.exmaple kb_config.py
/bin/cp -f basic_config.py.example basic_config.py
/bin/cp -f prompt_config.py.example prompt_config.py
# edit content of model_config.chatglm2.py
# vim disable auto indent => :set paste
/bin/cp -f model_config.chatglm2.py model_config.py
# no proxy to run ...
unset http_proxy
unset https_proxy
unset no_proxy
cd ${ENV_CWD}
python startup.py -a
# http://llm-finetune-chatchat-llm-demo.apps.demo-gpu.wzhlab.top/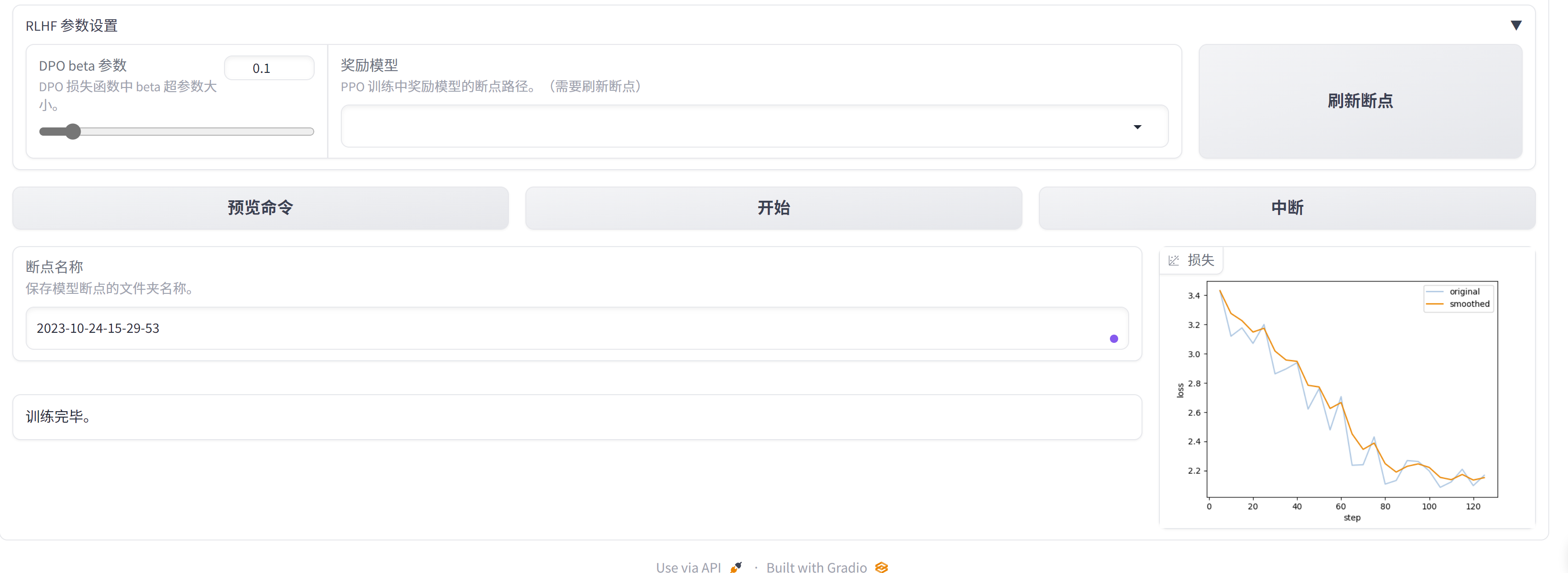
openshift AI
接下来,我们要来试试红帽官网的一个llm的例子,这个例子使用了openshift AI组件,里面使用calkit等挺奇怪的中间件,我们要尝试一下,体验一下吧。
- https://ai-on-openshift.io/demos/llm-chat-doc/llm-chat-doc/
install ODS
要想体验openshift AI,我们要先在operator hub里面装一下openshift data science,ODS是openshift AI的旧名字,过一段时间,名字就会改过来。

use alpha channel, by the time of 2023.11
我们实验用的很多东西,现在还在alpha阶段,所以记得选择alpha channel哦,,,以后,肯定会在stable channel里面。
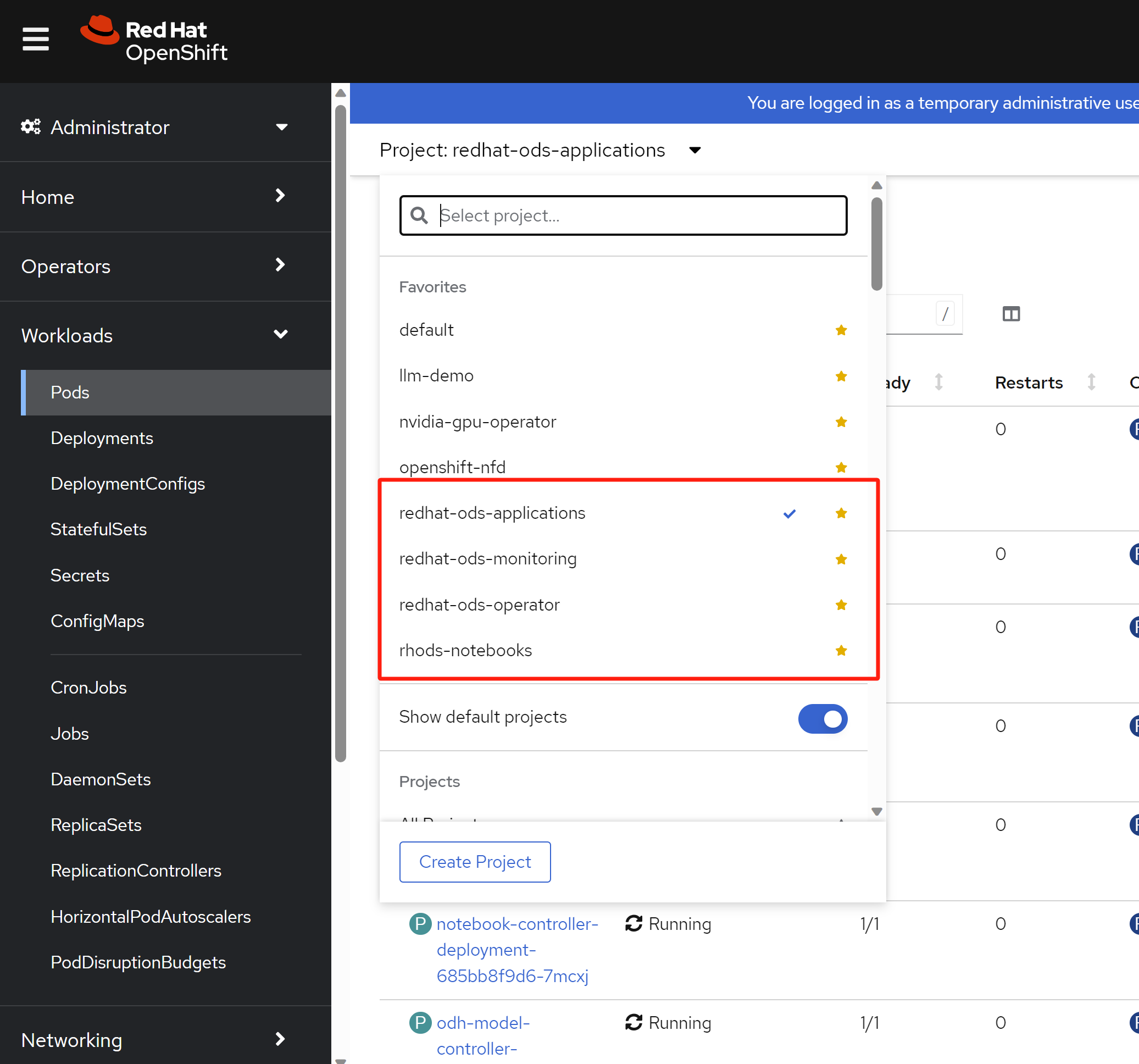
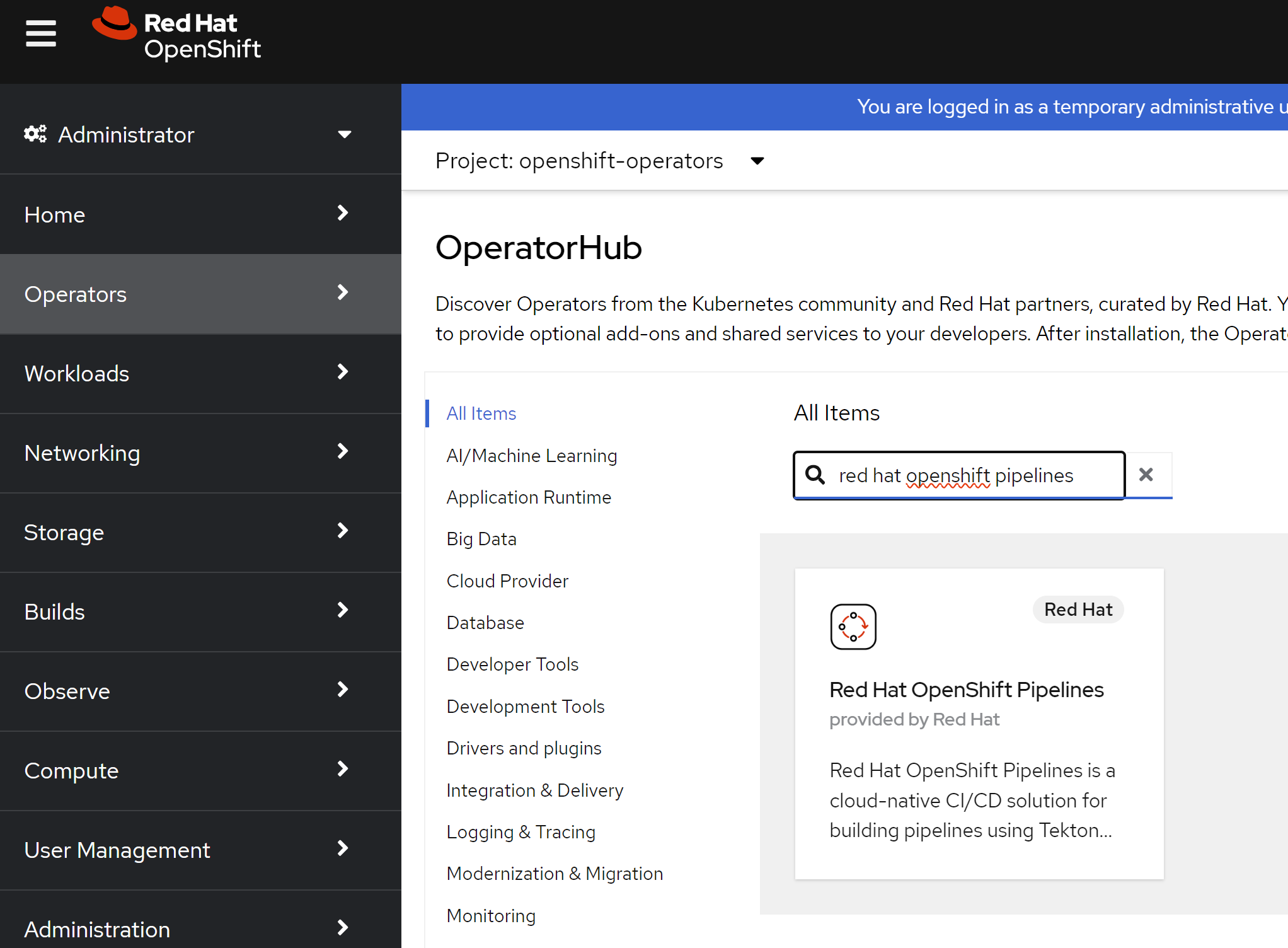
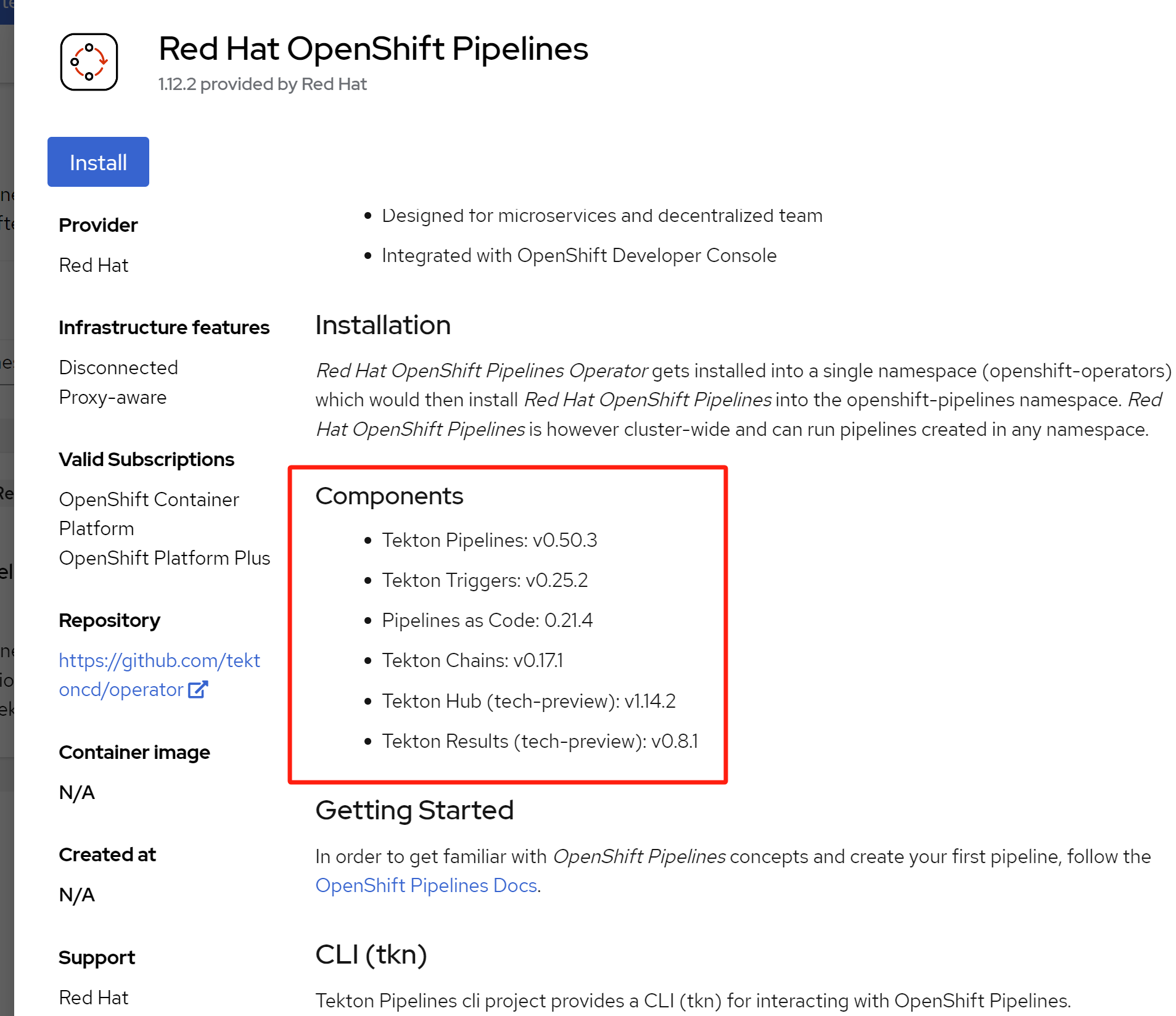
然后装一下 openshift pipeline,因为ODS里面的pipeline是用openshift pipeline实现的。
import custom notebook
实验用的jupyter基础镜像是定制的,所以我们需要导入。
- https://ai-on-openshift.io/odh-rhods/configuration/#cluster-settings
# quay.io/opendatahub-contrib/workbench-images:cuda-jupyter-langchain-c9s-py311_2023c_latest
# can not be recognized by notebook
# try to change name
podman pull quay.io/opendatahub-contrib/workbench-images:cuda-jupyter-langchain-c9s-py311_2023c_latest
podman tag quay.io/opendatahub-contrib/workbench-images:cuda-jupyter-langchain-c9s-py311_2023c_latest \
quay.io/wangzheng422/qimgs:ocp-ai-demo-v01
podman push quay.io/wangzheng422/qimgs:ocp-ai-demo-v01
# it turns out registry must configuredcheck the cache behavior
我们实验用的一个镜像,默认会下载模型文件,但是我们并不清楚他的行为,那么我们就找个云主机,运行一下,看看他到底下载了什么,除此之外,还干了什么。
- https://www.redhat.com/en/blog/how-use-gpus-containers-bare-metal-rhel-8
# we are on vultr, it use docker, and everything pre-installed
# do not upgrade the system, vultr's base system will break after upgrade
systemctl enable --now docker.service
# for ghcr.io/huggingface/text-generation-inference:1.1.0
mkdir -p /data/models-cache
# https://github.com/huggingface/text-generation-inference#run
# podman run -it --rm \
# -v /data//models-cache:/models-cache:Z \
# -e HUGGINGFACE_HUB_CACHE=/models-cache \
# -e MODEL_ID=google/flan-t5-xl \
# -e MAX_INPUT_LENGTH=1024 \
# -e MAX_TOTAL_TOKENS=2048 \
# ghcr.io/huggingface/text-generation-inference:1.1.0
docker run -it --rm \
--gpus all \
--shm-size 1g \
-e HUGGINGFACE_HUB_CACHE=/models-cache \
-e MODEL_ID=google/flan-t5-xl \
-e MAX_INPUT_LENGTH=1024 \
-e MAX_TOTAL_TOKENS=2048 \
-p 8080:80 \
-v /data//models-cache:/models-cache:Z \
ghcr.io/huggingface/text-generation-inference:1.1.0deploy using local directory
红帽官方上游的项目,并不能顺利的在离线环境上跑通,我们就fork出来,patch一下,来运行好了。
we clone upstream repo, and change it using local directory for pvc
- https://github.com/wangzheng422/llm-on-openshift
create HF-TGI instance
首先,我们运行 HF-TGI 这个演示,这个演示,就是运行一个llm模型的推理,以下部分,就是运行了一个huggingface的推理服务,然后暴露这个服务,等待前端调用。
# https://github.com/wangzheng422/llm-on-openshift/tree/wzh/hf_tgis_deployment/wzh
# we will use pvc: local-pvc-02
oc create --save-config -n llm-demo -f ./
# oc delete -n llm-demo -f ./create redis operator and instance
接下来,我们就要部署redis,redis的作用,是给LLM的RAG应用,做向量数据库,目前的实验例子里面,有两个向量数据库的实例,redis是一个,后面的pgvector是另外一个。个人推荐使用pgvector来做实验,简单一些。
deploy redis operator in version: 6.2.10-45
实验例子里面,redis的部署,有一个权限相关的配置是错误的,需要注意更正以下,否者redis里面的module就识别不到了。
# https://github.com/wangzheng422/llm-on-openshift/blob/wzh/redis_deployment/scc.yaml
# for redis 6
# https://github.com/RedisLabs/redis-enterprise-k8s-docs/blob/master/openshift/scc.yaml
oc create --save-config -n llm-demo -f scc.yaml
oc adm policy add-scc-to-user redis-enterprise-scc-v2 system:serviceaccount:llm-demo:redis-enterprise-operator
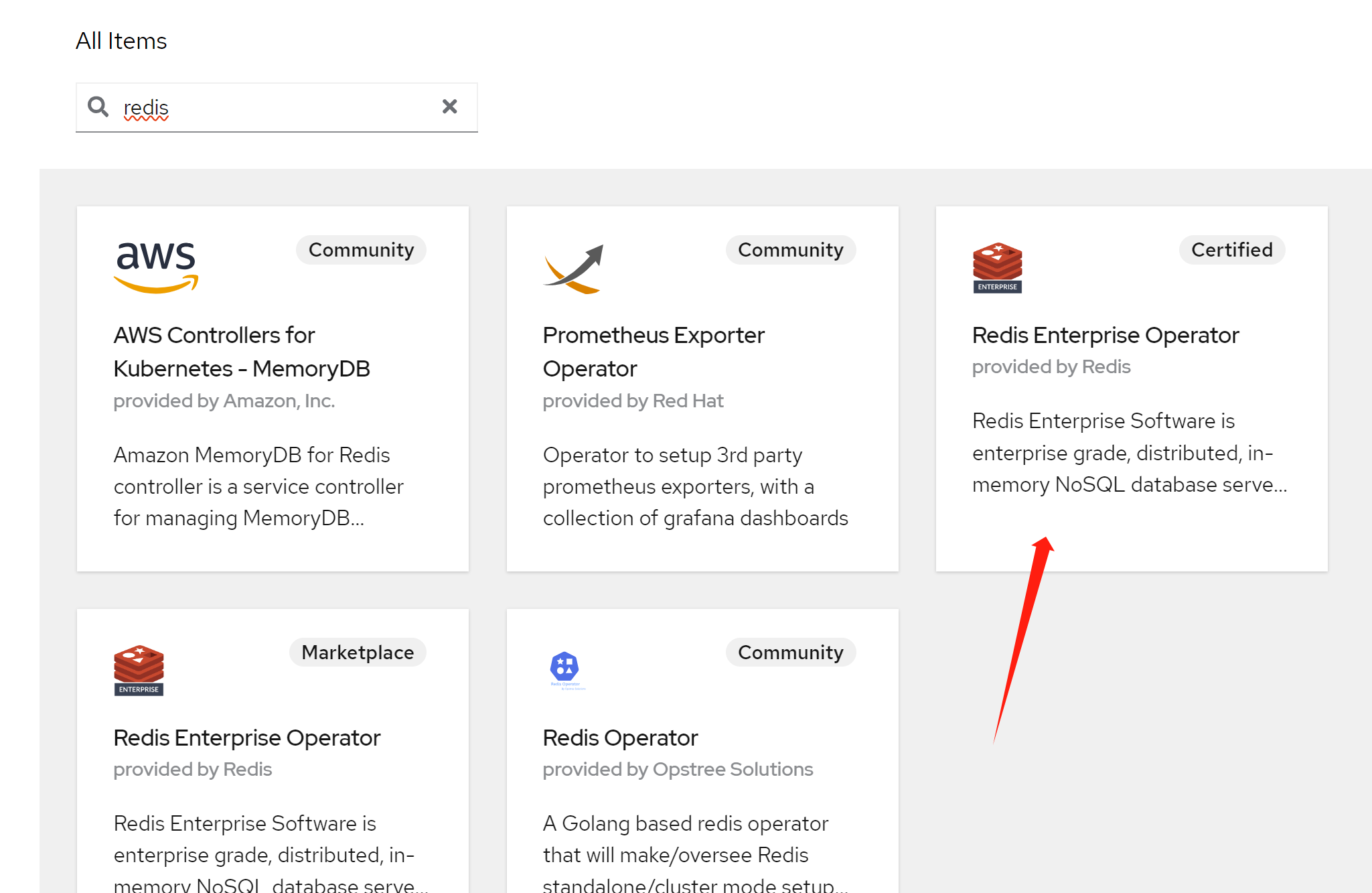
oc adm policy add-scc-to-user redis-enterprise-scc-v2 system:serviceaccount:llm-demo:rec装redis还是从operator hub里面进去,点击安装
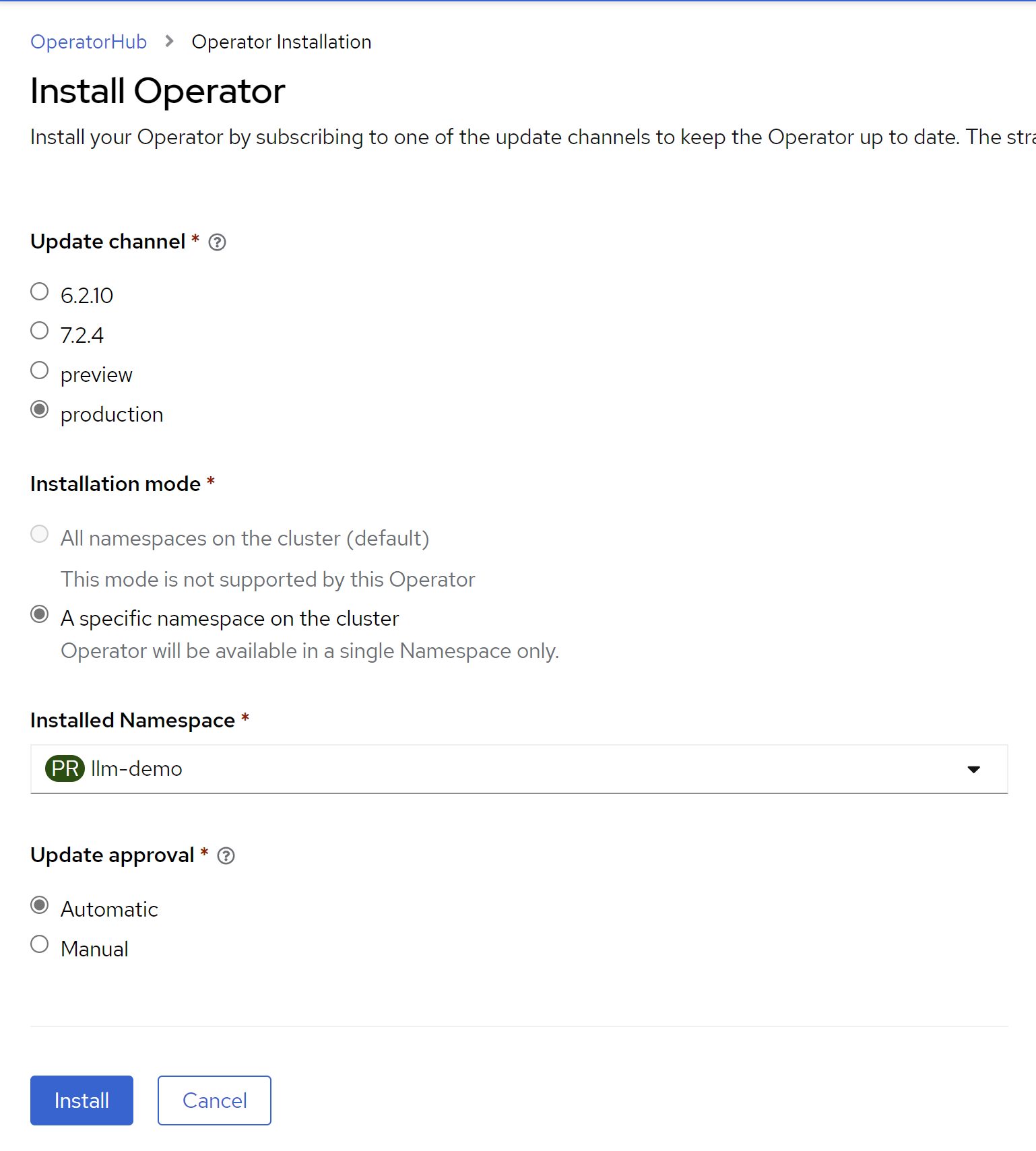
装完了operator,配置一下,创建redis服务实例。
# clear directory, and re-apply the scc
# if you want to re-install redis
oc adm policy add-scc-to-user redis-enterprise-scc-v2 system:serviceaccount:llm-demo:redis-enterprise-operator
oc adm policy add-scc-to-user redis-enterprise-scc-v2 system:serviceaccount:llm-demo:rec
cat << EOF > ${BASE_DIR}/data/install/redis-cluster.yaml
apiVersion: app.redislabs.com/v1
kind: RedisEnterpriseCluster
metadata:
name: rec
spec:
serviceAccountName: rec
redisEnterpriseNodeResources:
limits:
cpu: '4'
ephemeral-storage: 10Gi
memory: 8Gi
requests:
cpu: '4'
ephemeral-storage: 1Gi
memory: 8Gi
bootstrapperImageSpec:
repository: registry.connect.redhat.com/redislabs/redis-enterprise-operator
clusterCredentialSecretName: rec
# for testing, we only run 1 node instanc
nodes: 1
# we disable pod anti affinity, so redis pod can run on same host
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution: []
persistentSpec:
enabled: true
storageClassName: hostpath-csi
volumeSize: 20Gi
createServiceAccount: true
username: admin@wzhlab.top
clusterCredentialSecretRole: ''
podStartingPolicy:
enabled: false
startingThresholdSeconds: 540
redisEnterpriseServicesRiggerImageSpec:
repository: registry.connect.redhat.com/redislabs/services-manager
redisEnterpriseImageSpec:
imagePullPolicy: IfNotPresent
repository: registry.connect.redhat.com/redislabs/redis-enterprise
uiServiceType: ClusterIP
clusterCredentialSecretType: kubernetes
servicesRiggerSpec:
databaseServiceType: 'cluster_ip,headless'
serviceNaming: bdb_name
services:
apiService:
type: ClusterIP
EOF
oc create --save-config -n llm-demo -f ${BASE_DIR}/data/install/redis-cluster.yaml
# oc delete -n llm-demo -f ${BASE_DIR}/data/install/redis-cluster.yaml
# before create database, we need to import module
# https://docs.redis.com/latest/stack/install/add-module-to-cluster/
oc create route passthrough rec-ui --service=rec-ui --port=8443 -n llm-demo
oc get route -n llm-demo
# NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
# rec-ui rec-ui-llm-demo.apps.demo-gpu.wzhlab.top rec-ui 8443 passthrough None
# open the redis management UI
# https://rec-ui-llm-demo.apps.demo-gpu.wzhlab.top/new#
oc get secret rec -n llm-demo -o jsonpath="{.data}" | jq 'map_values(@base64d)'
# {
# "password": "gv7AZB8P",
# "username": "admin@wzhlab.top"
# }
# login using above username and password
# get the search model
# oc cp llm-demo/rec-0:/opt/persistent/modules/search/20804/rhel8/x86_64/module.so ./module.so
# oc exec -n llm-demo rec-0 -- tar zcf - /opt/persistent/modules/search > search.tgz然后,我们就能登录redis的管理界面了.
我们也能看到model都加载了。
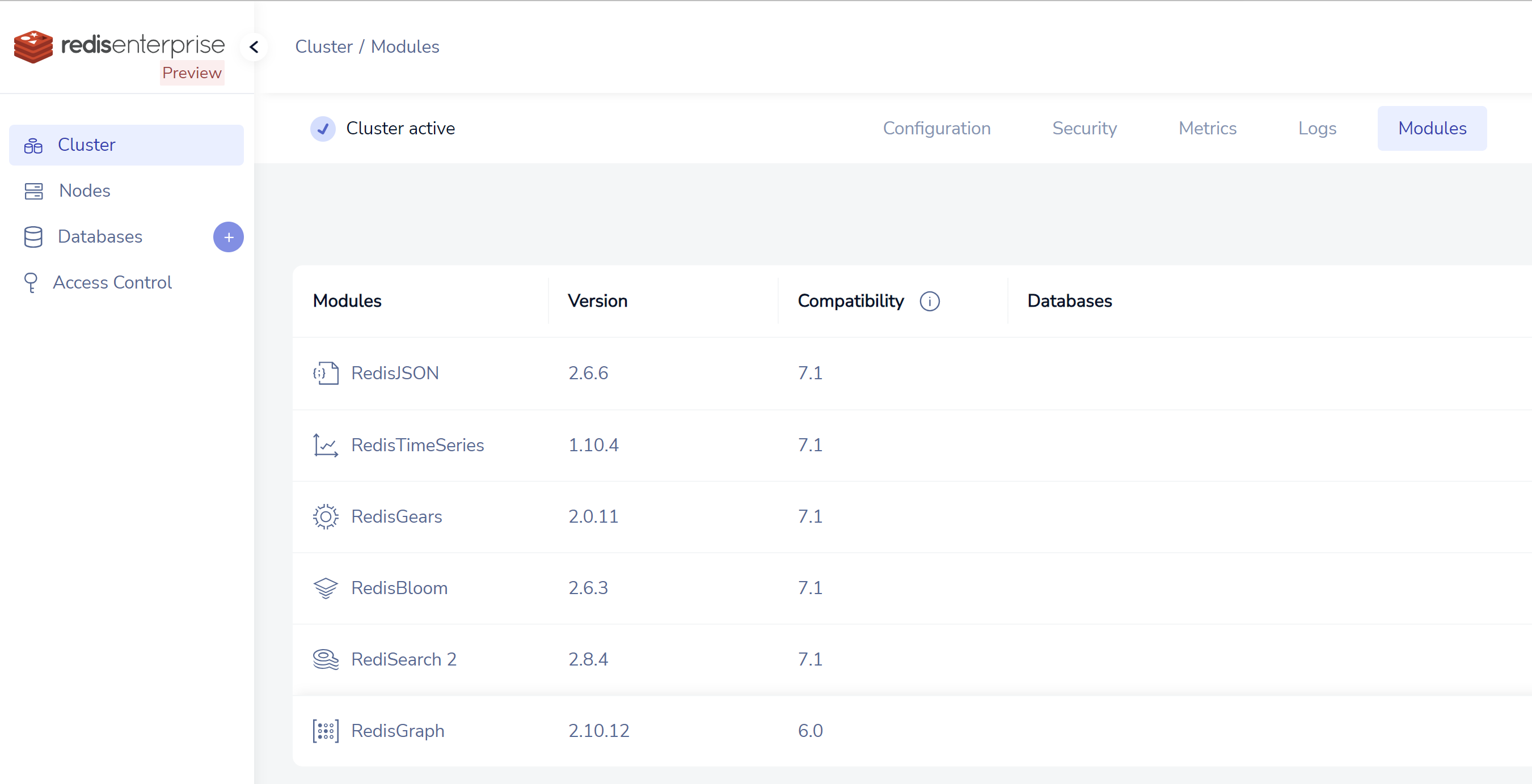
创建一个DB,承载我们的向量数据库。
# create database
# the memory limit for free redis version is aroung 4GB, it is the cluster memory / 2
cat << EOF > ${BASE_DIR}/data/install/redis-db.yaml
apiVersion: app.redislabs.com/v1alpha1
kind: RedisEnterpriseDatabase
metadata:
name: my-doc
spec:
memorySize: 4GB
modulesList:
- name: search
version: 2.8.4
persistence: snapshotEvery12Hour
replication: false
tlsMode: disabled
type: redis
# shardCount: 4
EOF
oc create --save-config -n llm-demo -f ${BASE_DIR}/data/install/redis-db.yaml
# oc delete -n llm-demo -f ${BASE_DIR}/data/install/redis-db.yaml
oc get RedisEnterpriseDatabase/my-doc -n llm-demo -o json | jq .status.internalEndpoints
# [
# {
# "host": "redis-13858.rec.llm-demo.svc.cluster.local",
# "port": 13858
# }
# ]
oc get secret -n llm-demo redb-my-doc -o jsonpath="{.data}" | jq 'map_values(@base64d)'
# {
# "password": "ABmKLkR0",
# "port": "13858",
# "service_name": "my-doc-headless",
# "service_names": "my-doc, my-doc-headless"
# }
# VAR_HOST=`oc get RedisEnterpriseDatabase/my-doc -n llm-demo -o json | jq .status.internalEndpoints[0].host -r`
VAR_PWD=`oc get secret -n llm-demo redb-my-doc -o jsonpath="{.data}" | jq 'map_values(@base64d)' | jq -r .password`
VAR_PORT=`oc get secret -n llm-demo redb-my-doc -o jsonpath="{.data}" | jq 'map_values(@base64d)' | jq -r .port`
VAR_REDIS="redis://default:${VAR_PWD}@my-doc-headless.llm-demo.svc.cluster.local:${VAR_PORT}"
echo $VAR_REDIS
# redis://default:Ygg8FgJc@my-doc-headless.llm-demo.svc.cluster.local:16432
create pg with vector
redis的向量数据不要用,或者说,有license限制,现在,我们来搞一个pg vector,这个用起来更自由,更方便。
- https://github.com/wangzheng422/llm-on-openshift/blob/main/pgvector_deployment/README.md
# on helper node
cd ~/tmp
git clone https://github.com/wangzheng422/llm-on-openshift
cd ~/tmp/llm-on-openshift
cd pgvector_deployment
oc new-project pgvector-demo
oc project pgvector-demo
oc apply -f ./
# active the vector
oc get svc -n pgvector-demo
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# postgresql ClusterIP 172.22.163.117 <none> 5432/TCP 36m
# go into pg to create vector
oc rsh -n pgvector-demo deploy/postgresql
sh-5.1$ psql -d vectordb -c "CREATE EXTENSION vector;"
CREATE EXTENSIONuse it to create index and search
我们来试试向量数据库
- https://github.com/wangzheng422/llm-on-openshift/blob/main/examples/notebooks/langchain/Langchain-PgVector-Ingest.ipynb
- https://github.com/wangzheng422/llm-on-openshift/blob/main/examples/notebooks/langchain/Langchain-PgVector-Query.ipynb
# to see what is in the database
pg_dump vectordb
psql -d vectordb
\dt
List of relations
Schema | Name | Type | Owner
--------+-------------------------+-------+----------
public | langchain_pg_collection | table | vectordb
public | langchain_pg_embedding | table | vectordb
(2 rows)
SELECT * FROM langchain_pg_collection;
name | cmetadata | uuid
----------------+-----------+--------------------------------------
documents_test | null | 52012087-d48d-433d-9c78-859035b8f622
(1 row)
select * from langchain_pg_embedding;
.....
so many
.....
\d+ langchain_pg_embedding
Table "public.langchain_pg_embedding"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
---------------+-------------------+-----------+----------+---------+----------+-------------+--------------+-------------
collection_id | uuid | | | | plain | | |
embedding | vector | | | | extended | | |
document | character varying | | | | extended | | |
cmetadata | json | | | | extended | | |
custom_id | character varying | | | | extended | | |
uuid | uuid | | not null | | plain | | |
Indexes:
"langchain_pg_embedding_pkey" PRIMARY KEY, btree (uuid)
Foreign-key constraints:
"langchain_pg_embedding_collection_id_fkey" FOREIGN KEY (collection_id) REFERENCES langchain_pg_collection(uuid) ON DELETE CASCADE
Access method: heap
我们也可以从jupyter里面,用代码的方式,来访问向量数据,这里是代码访问PG vector
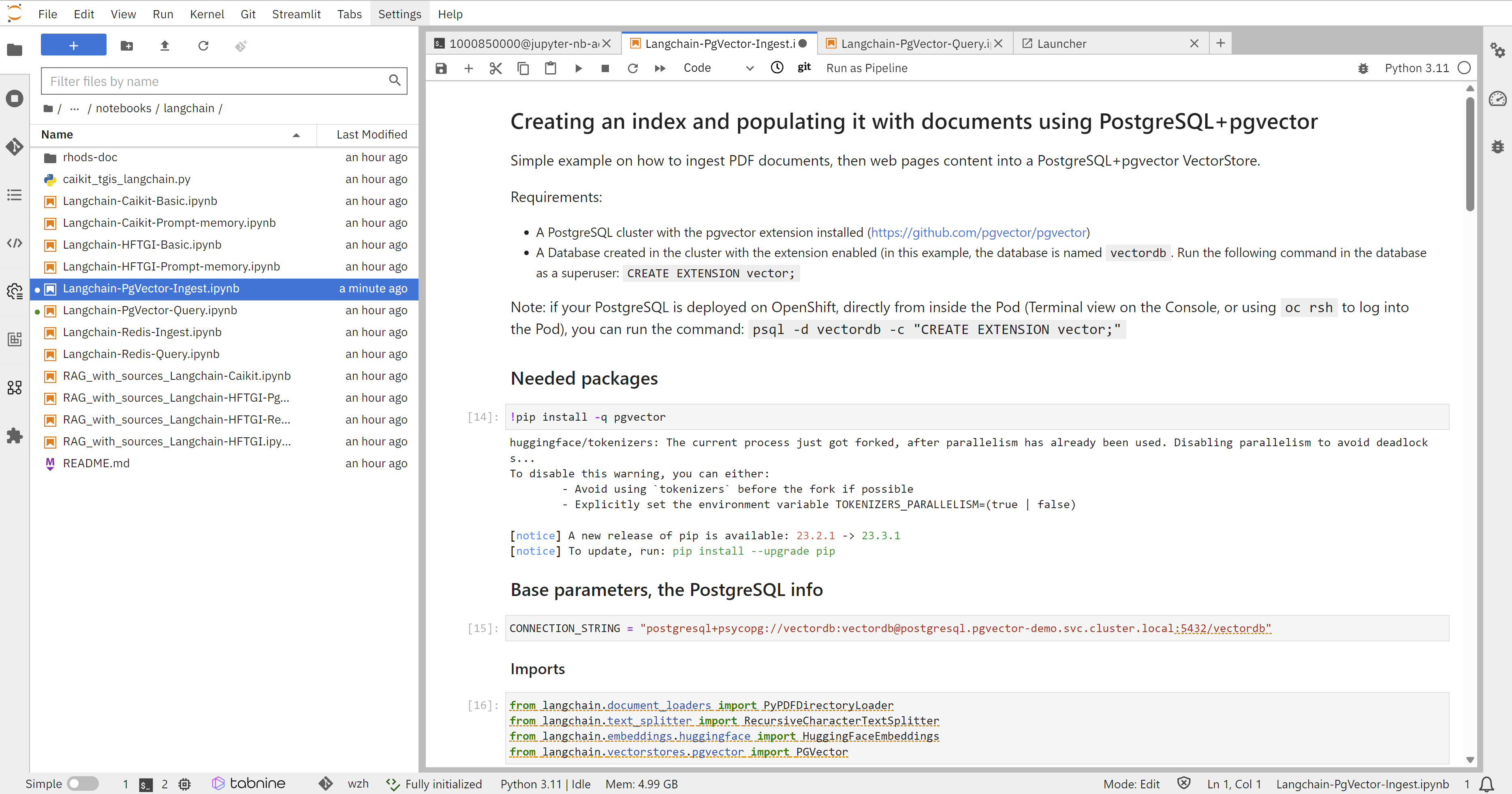
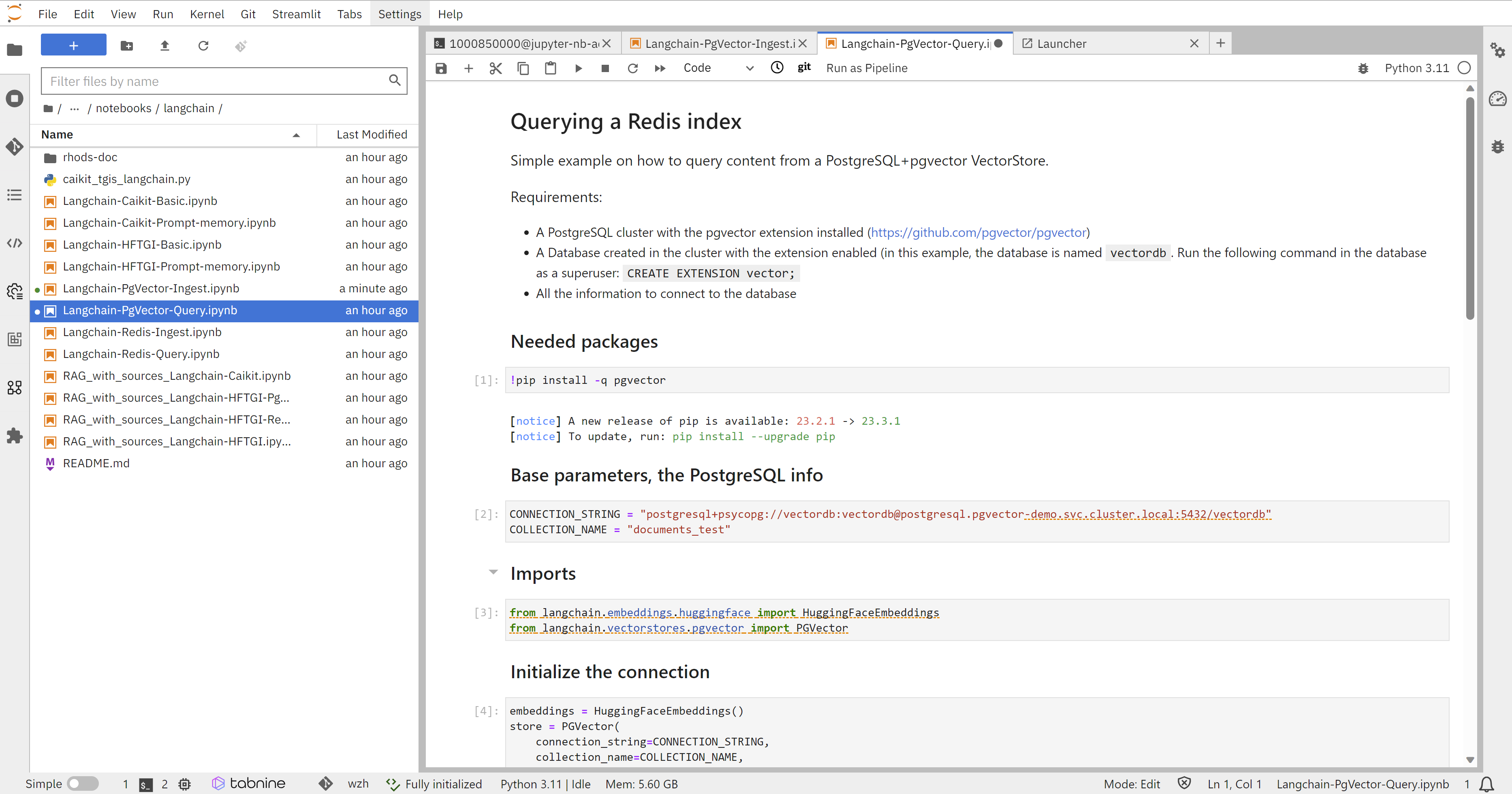
这里是代码访问redis vector
Simple Chat with memory using HFTGI
好啦,我们准备好了一个LLM的推理服务,还准备好了一个向量数据库,接下来,我们就要来试试,把这两个东西结合起来,做一个简单的聊天机器人。
gradio-hftgi-memory
- https://github.com/rh-aiservices-bu/llm-on-openshift/blob/main/examples/ui/gradio/gradio-hftgi-memory/README.md
# https://github.com/wangzheng422/llm-on-openshift/tree/wzh/examples/ui/gradio/gradio-hftgi-memory/deployment/wzh
# /bin/rm -f ${BASE_DIR}/wzh/*
oc create -n llm-demo -f ${BASE_DIR}/wzh/
# oc delete -n llm-demo -f ${BASE_DIR}/wzh/我们部署了一个gradio的web服务,这个服务,会调用我们的LLM推理服务,来做推理,然后,把推理结果,展示在web页面上。
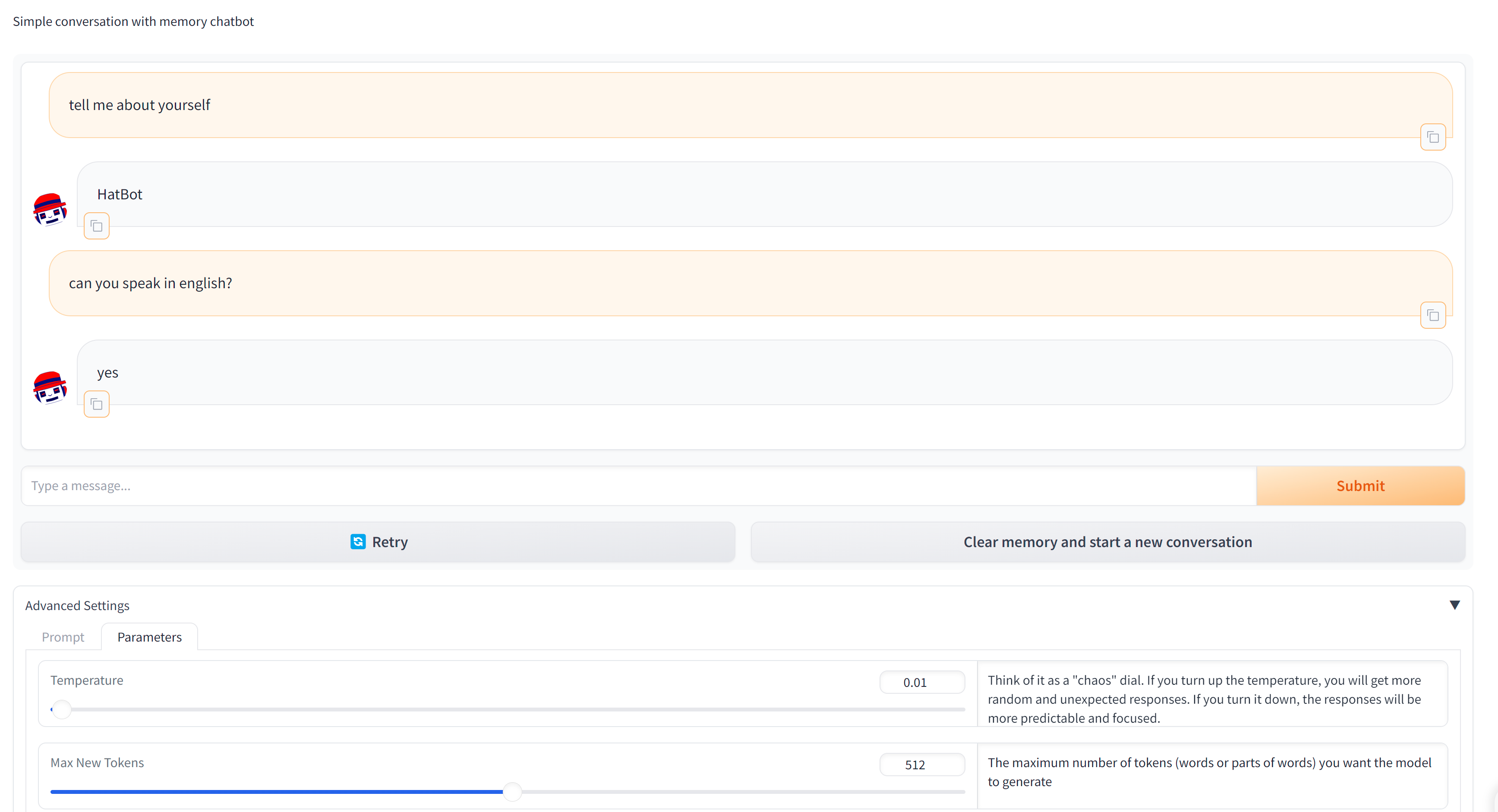
Chatbot+HFTGI+Redis
接下来,我们展示一个更复杂的例子,我们回先用代码的方式,访问一个RAG应用,这个应用使用redis vector数据库作为支撑,然后调用LLM的推理服务。
gradio-hftgi-rag-redis
- https://github.com/rh-aiservices-bu/llm-on-openshift/blob/main/examples/ui/gradio/gradio-hftgi-rag-redis/README.md
create index
我们先在redis vector里面创建必要的数据。具体做的事情,就是把我们准备好的pdf向量化,然后存入redis vector里面。
Langchain-Redis-Ingest.ipynb
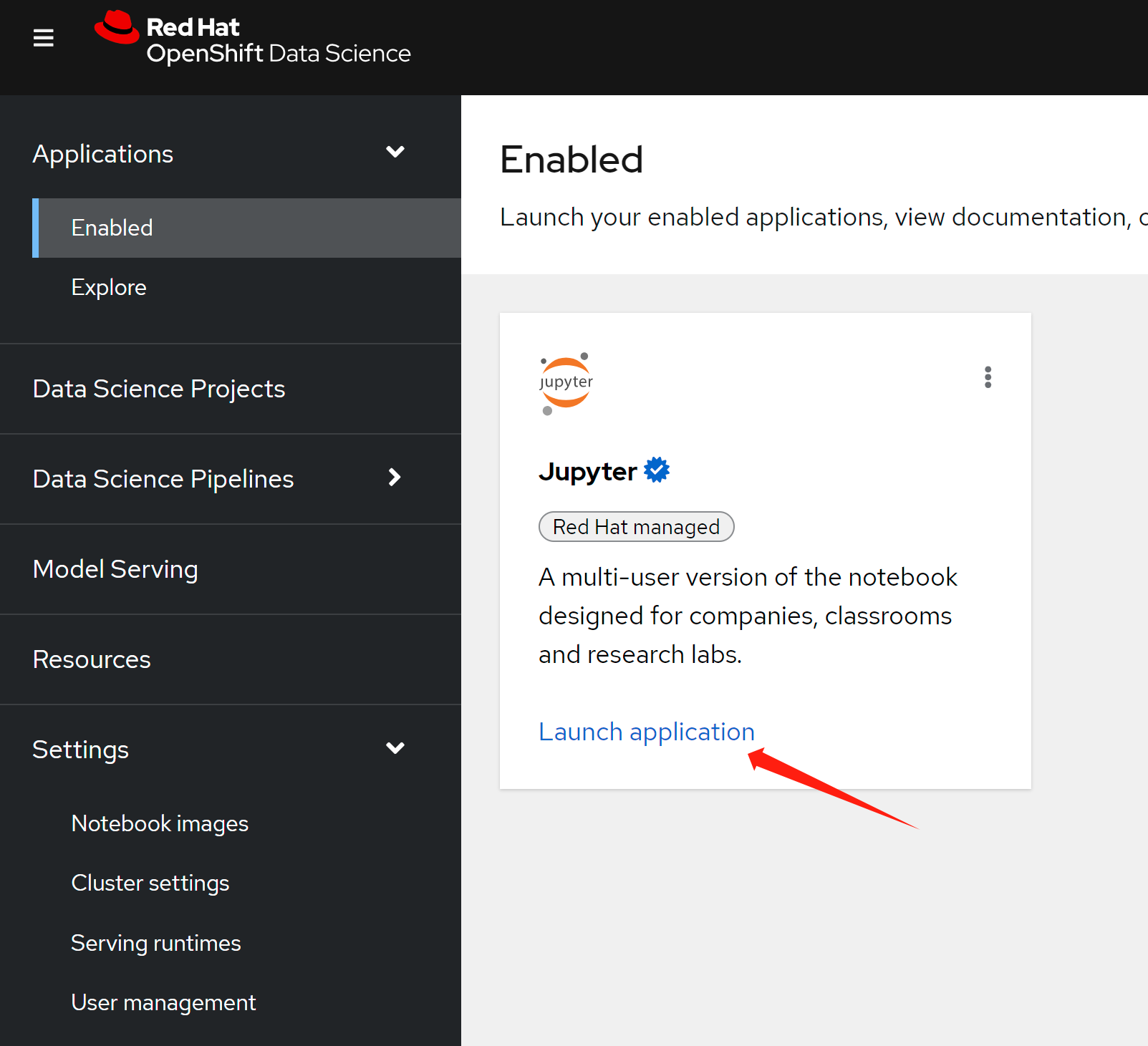
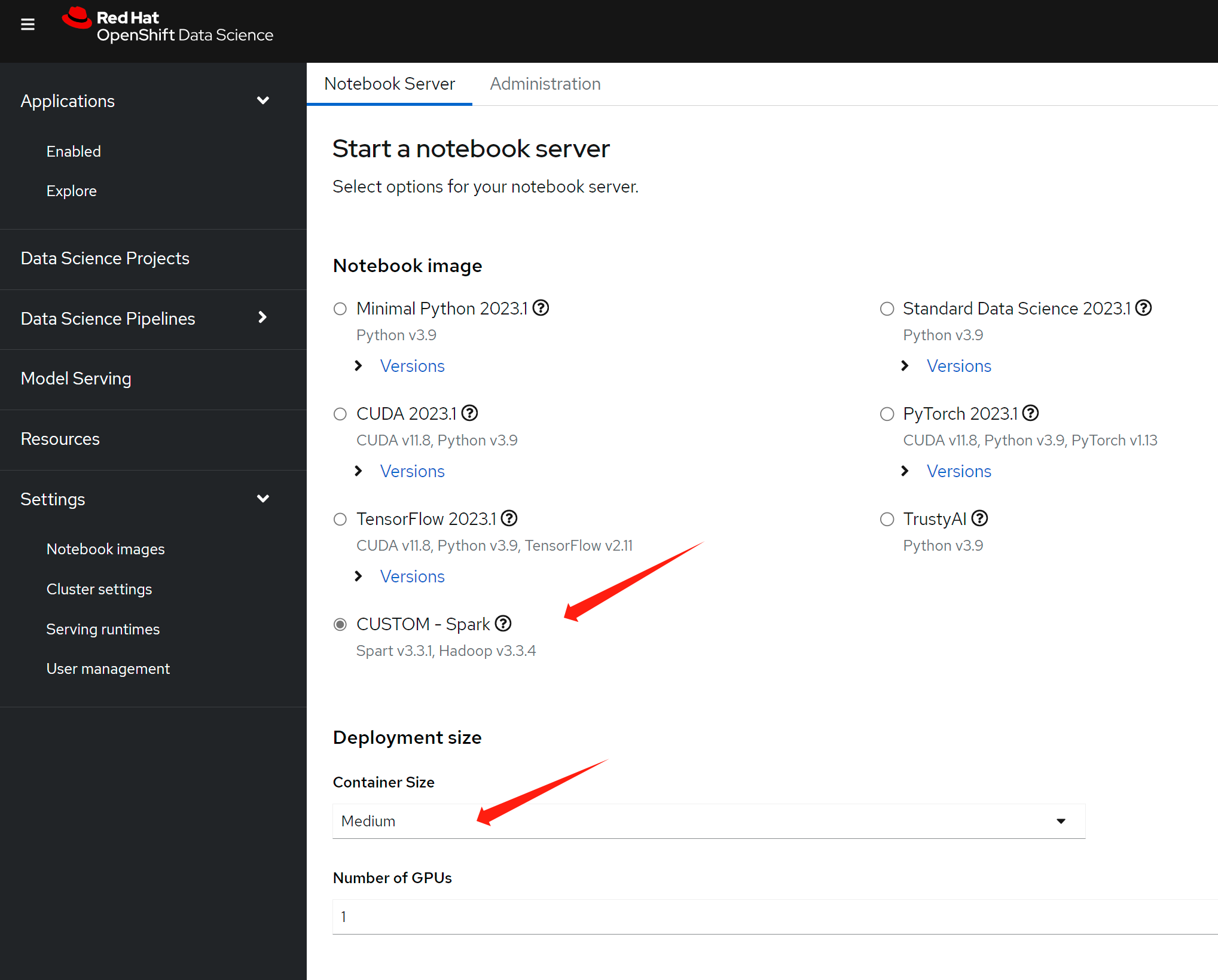
open this notebook
- https://github.com/rh-aiservices-bu/llm-on-openshift/blob/main/examples/notebooks/langchain/Langchain-Redis-Ingest.ipynb
run it step by step, or all
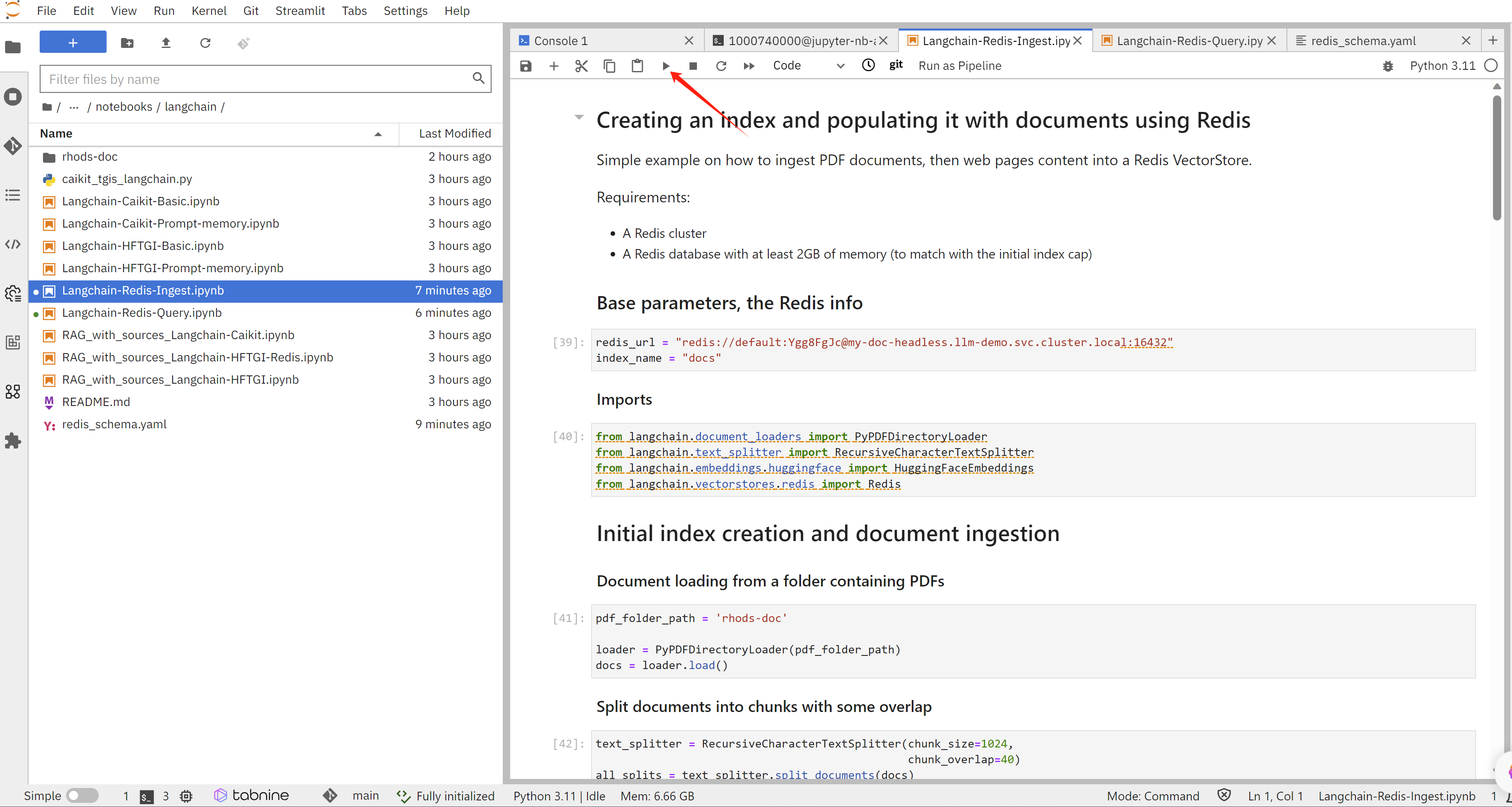
deploy
然后,我们部署一个前端应用,这个应用会调用redis,访问向量数据,然后再访问LLM。
# we need to build image for module cache
# on vultr
systemctl enable --now docker.service
mkdir -p /data/llm-build
cd /data/llm-build
cat << EOF > /data/llm-build/build.dockerfile
FROM quay.io/rh-aiservices-bu/gradio-hftgi-rag-redis:latest
RUN python app.py || true
EOF
docker build -t quay.io/wangzheng422/qimgs:2023-11-14-gradio-hftgi-rag-redis-01 -f build.dockerfile .
docker push quay.io/wangzheng422/qimgs:2023-11-14-gradio-hftgi-rag-redis-01
# docker run -it -d \
# --name llm-build \
# --gpus all \
# --shm-size 1g \
# quay.io/rh-aiservices-bu/gradio-hftgi-rag-redis:latest
# docker export llm-build | docker import - quay.io/wangzheng422/qimgs:2023-11-14-gradio-hftgi-rag-redis
# docker push quay.io/wangzheng422/qimgs:2023-11-14-gradio-hftgi-rag-redis
# go back to helper node
# https://github.com/wangzheng422/llm-on-openshift/tree/wzh/examples/ui/gradio/gradio-hftgi-rag-redis/deployment/wzh
oc create -n llm-demo -f ${BASE_DIR}/wzh/
# oc delete -n llm-demo -f ${BASE_DIR}/wzh/then, you can see the webpage:
Caikit-TGIS-pgvector
之前,我们都是使用huggingface的text generator rest API访问LLM的推理服务,现在我们使用红帽官方的Caikit-TGIS框架,来访问LLM的推理服务。
- https://github.com/opendatahub-io/caikit-tgis-serving
install
首先,我们要部署caikit-tgis框架,这个框架还挺复杂,有servserless, kserv等框架组成。
- https://github.com/opendatahub-io/caikit-tgis-serving/blob/main/demo/kserve/install-manual.md
# on helper
cd ~/tmp
git clone https://github.com/opendatahub-io/caikit-tgis-serving
cd caikit-tgis-serving/demo/kserve
export TARGET_OPERATOR=rhods
source ./scripts/env.sh
source ./scripts/utils.sh
export TARGET_OPERATOR_TYPE=$(getOpType $TARGET_OPERATOR)
export TARGET_OPERATOR_NS=$(getOpNS)
export KSERVE_OPERATOR_NS=$(getKserveNS)
echo $TARGET_OPERATOR_TYPE
# rhods
echo $TARGET_OPERATOR_NS
# redhat-ods-operator
echo $KSERVE_OPERATOR_NS
# redhat-ods-applications
# Install the Service Mesh operators.
oc apply -f custom-manifests/service-mesh/operators.yaml
oc wait --for=condition=ready pod -l name=istio-operator -n openshift-operators --timeout=300s
# pod/istio-operator-c76f5d6db-6nfgx condition met
oc create ns istio-system
oc apply -f custom-manifests/service-mesh/smcp.yaml
wait_for_pods_ready "app=istiod" "istio-system"
# All app=istiod pods in 'istio-system' namespace are running and ready.
wait_for_pods_ready "app=istio-ingressgateway" "istio-system"
# All app=istio-ingressgateway pods in 'istio-system' namespace are running and ready.
wait_for_pods_ready "app=istio-egressgateway" "istio-system"
# All app=istio-egressgateway pods in 'istio-system' namespace are running and ready.
oc wait --for=condition=ready pod -l app=istiod -n istio-system --timeout=300s
oc wait --for=condition=ready pod -l app=istio-ingressgateway -n istio-system --timeout=300s
oc wait --for=condition=ready pod -l app=istio-egressgateway -n istio-system --timeout=300s
# Install Knative Serving.
oc create ns ${KSERVE_OPERATOR_NS}
oc create ns knative-serving
oc -n istio-system apply -f custom-manifests/service-mesh/default-smmr.yaml
oc apply -f custom-manifests/serverless/operators.yaml
wait_for_csv_installed serverless-operator openshift-serverless
# [START] Watching if CSV "serverless-operator" is installed
# [END] CSV "serverless-operator" is successfully installed
oc wait --for=condition=ready pod -l name=knative-openshift -n openshift-serverless --timeout=300s
oc wait --for=condition=ready pod -l name=knative-openshift-ingress -n openshift-serverless --timeout=300s
oc wait --for=condition=ready pod -l name=knative-operator -n openshift-serverless --timeout=300s
# Create a KnativeServing Instance.
oc apply -f custom-manifests/serverless/knativeserving-istio.yaml
sleep 15
wait_for_pods_ready "app=controller" "knative-serving"
wait_for_pods_ready "app=net-istio-controller" "knative-serving"
wait_for_pods_ready "app=net-istio-webhook" "knative-serving"
wait_for_pods_ready "app=autoscaler-hpa" "knative-serving"
wait_for_pods_ready "app=domain-mapping" "knative-serving"
wait_for_pods_ready "app=webhook" "knative-serving"
oc delete pod -n knative-serving -l app=activator --force --grace-period=0
oc delete pod -n knative-serving -l app=autoscaler --force --grace-period=0
wait_for_pods_ready "app=activator" "knative-serving"
wait_for_pods_ready "app=autoscaler" "knative-serving"
# Generate a wildcard certification for a gateway using OpenSSL.
# !!!! run on rhel9 !!!!
export BASE_DIR=/tmp/kserve
export BASE_CERT_DIR=${BASE_DIR}/certs
export DOMAIN_NAME=$(oc get ingresses.config.openshift.io cluster -o jsonpath='{.spec.domain}' | awk -F'.' '{print $(NF-1)"."$NF}')
export COMMON_NAME=$(oc get ingresses.config.openshift.io cluster -o jsonpath='{.spec.domain}')
mkdir ${BASE_DIR}
mkdir ${BASE_CERT_DIR}
./scripts/generate-wildcard-certs.sh ${BASE_CERT_DIR} ${DOMAIN_NAME} ${COMMON_NAME}
export TARGET_CUSTOM_CERT=${BASE_CERT_DIR}/wildcard.crt
export TARGET_CUSTOM_KEY=${BASE_CERT_DIR}/wildcard.key
# if do not have rhel9, create key and set env
export TARGET_CUSTOM_CERT=/etc/crts/wzhlab.top.crt
export TARGET_CUSTOM_KEY=/etc/crts/wzhlab.top.key
# Create the Knative gateway.
oc create secret tls wildcard-certs --cert=${TARGET_CUSTOM_CERT} --key=${TARGET_CUSTOM_KEY} -n istio-system
oc apply -f custom-manifests/serverless/gateways.yaml
# Apply the Istio monitoring resources.
oc apply -f ./custom-manifests/service-mesh/istiod-monitor.yaml
oc apply -f ./custom-manifests/service-mesh/istio-proxies-monitor.yaml
# Apply the cluster role to allow Prometheus access.
oc apply -f ./custom-manifests/metrics/kserve-prometheus-k8s.yaml
# Deploy KServe with Open Data Hub Operator 2.0.
OPERATOR_LABEL="control-plane=controller-manager"
if [[ ${TARGET_OPERATOR_TYPE} == "rhods" ]];
then
OPERATOR_LABEL="name=rhods-operator"
fi
oc create ns ${TARGET_OPERATOR_NS}
oc create -f custom-manifests/opendatahub/${TARGET_OPERATOR}-operators-2.x.yaml
sleep 10
wait_for_pods_ready "${OPERATOR_LABEL}" "${TARGET_OPERATOR_NS}"
oc create -f custom-manifests/opendatahub/kserve-dsc.yaml
# install codeflare operator
# https://github.com/project-codeflare/codeflare
# https://github.com/kserve/modelmesh-serving
# modelmeshserving to Removed, can not active, do not know why.create minio image
为了实验效果,我们需要把llama2的模型文件,导入到实验中来,这就需要我们做minio的定制镜像。
on helper
我们在本地,已经有llama2的模型文件了,那么我们在本地做,然后push到镜像仓库里面去,这样比较快,毕竟模型文件太大了。
# on helper
mkdir -p /data01/git_env
cd /data01/git_env
git clone https://github.com/wangzheng422/modelmesh-minio-examples
cd modelmesh-minio-examples
git checkout wzh
/bin/cp -r /data01/huggingface/meta-llama-Llama-2-7b-chat-hf ./Llama-2-7b-chat-hf
mv Llama-2-7b-chat-hf llama2
mkdir -p ./Llama-2-7b-chat-hf/artifacts
/bin/mv ./llama2/* ./Llama-2-7b-chat-hf/artifacts/
rm -rf llama2/
podman build -t quaylab.infra.wzhlab.top:5443/wangzheng422/qimgs:modelmesh-minio-llama-2-7b-chat-hf -f Dockerfile .
podman push quaylab.infra.wzhlab.top:5443/wangzheng422/qimgs:modelmesh-minio-llama-2-7b-chat-hf
on vultr
如果我们本地没有llama2的模型文件,那么我们就去找一个云主机,制作minio镜像,让后push到镜像仓库里面去。在云主机上做,是目前看到的最快的做法。
# on vultr
mkdir -p /data/env/
conda create -y -p /data/env/chatchat python=3.10
conda init bash
conda activate /data/env/chatchat
# conda deactivate
pip install --upgrade huggingface_hub
mkdir -p /data/git
cd /data/git
git clone https://github.com/wangzheng422/modelmesh-minio-examples
cd modelmesh-minio-examples
git checkout wzh
# on helper
# for chatglm2-6b
VAR_NAME=meta-llama/Llama-2-7b-chat-hf
VAR_NAME_FULL=${VAR_NAME#*/}
echo $VAR_NAME_FULL
# Llama-2-7b-chat-hf
mkdir -p ${VAR_NAME_FULL}
while true; do
huggingface-cli download --token ${HUGGINGFACE_TOKEN} --repo-type model --revision main --local-dir ./${VAR_NAME_FULL} --local-dir-use-symlinks False --resume-download ${VAR_NAME}
if [ $? -eq 0 ]; then
break
fi
sleep 1 # Optional: waits for 1 second before trying again
done
podman build -t quay.io/wangzheng422/qimgs:modelmesh-minio-llama-2-7b-chat-hf -f Dockerfile .
podman push quay.io/wangzheng422/qimgs:modelmesh-minio-llama-2-7b-chat-hf
deploy model
接下来,我们就部署模型,步骤比较复杂,都写在下面啦,官方的部署,有些问题,做不下去,需要用我patch过后的配置来搞。当然,过一段时间以后,我patch过的东西,估计也可能运行不起来。
- https://github.com/wangzheng422/caikit-tgis-serving/blob/main/demo/kserve/deploy-remove.md
# on helper
cd ~/tmp
cd caikit-tgis-serving/demo/kserve
export TARGET_OPERATOR=rhods
source ./scripts/env.sh
source ./scripts/utils.sh
export TARGET_OPERATOR_TYPE=$(getOpType $TARGET_OPERATOR)
export TARGET_OPERATOR_NS=$(getOpNS)
export KSERVE_OPERATOR_NS=$(getKserveNS)
# Deploy the MinIO image that contains the LLM model.
ACCESS_KEY_ID=admin
SECRET_ACCESS_KEY=password
MINIO_NS=minio
oc new-project ${MINIO_NS}
sed "s|image: .*|image: quaylab.infra.wzhlab.top:5443/wangzheng422/qimgs:modelmesh-minio-llama-2-7b-chat-hf|g" ./custom-manifests/minio/minio.yaml | tee ./minio-current.yaml | oc -n ${MINIO_NS} apply -f -
# oc apply -f ./custom-manifests/minio/minio.yaml -n ${MINIO_NS}
sed "s/<minio_ns>/$MINIO_NS/g" ./custom-manifests/minio/minio-secret.yaml | tee ./minio-secret-current.yaml | oc -n ${MINIO_NS} apply -f -
sed "s/<minio_ns>/$MINIO_NS/g" ./custom-manifests/minio/serviceaccount-minio.yaml | tee ./serviceaccount-minio-current.yaml | oc -n ${MINIO_NS} apply -f -
# Endpoint: http://10.133.0.36:9000 http://127.0.0.1:9000
# Browser Access:
# http://10.133.0.36:9000 http://127.0.0.1:9000
# Object API (Amazon S3 compatible):
# Go: https://docs.min.io/docs/golang-client-quickstart-guide
# Java: https://docs.min.io/docs/java-client-quickstart-guide
# Python: https://docs.min.io/docs/python-client-quickstart-guide
# JavaScript: https://docs.min.io/docs/javascript-client-quickstart-guide
# .NET: https://docs.min.io/docs/dotnet-client-quickstart-guide
# IAM initialization complete
cat minio-secret-current.yaml | grep endpoint
# serving.kserve.io/s3-endpoint: minio.minio.svc:9000 # replace with your s3 endpoint e.g minio-service.kubeflow:9000
# Deploy the LLM model with Caikit+TGIS Serving runtime
export TEST_NS=kserve-demo
oc new-project ${TEST_NS}
oc apply -f ./custom-manifests/caikit/caikit-tgis-servingruntime.yaml -n ${TEST_NS}
# oc delete -f ./custom-manifests/caikit/caikit-tgis-servingruntime.yaml -n ${TEST_NS}
# to this step, pod is not created
oc apply -f ./minio-secret-current.yaml -n ${TEST_NS}
oc create -f ./serviceaccount-minio-current.yaml -n ${TEST_NS}
# change ths url to s3://minio.minio.svc.cluster.local:9000/modelmesh-example-models/llm/models/flan-t5-small-caikit
oc apply -f ./custom-manifests/caikit/caikit-tgis-isvc.yaml -n ${TEST_NS}
# oc delete -f ./custom-manifests/caikit/caikit-tgis-isvc.yaml -n ${TEST_NS}
# Error from server (storageUri, must be one of: [gs://, s3://, pvc://, file://, https://, http://, hdfs://, webhdfs://] or match https://{}.blob.core.windows.net/{}/{} or be an absolute or relative local path. StorageUri [proto://path/to/model] is not supported.): error when creating "./custom-manifests/caikit/caikit-tgis-isvc.yaml": admission webhook "inferenceservice.kserve-webhook-server.validator" denied the request: storageUri, must be one of: [gs://, s3://, pvc://, file://, https://, http://, hdfs://, webhdfs://] or match https://{}.blob.core.windows.net/{}/{} or be an absolute or relative local path. StorageUri [proto://path/to/model] is not supported.
# oc delete -f ./custom-manifests/caikit/caikit-tgis-isvc.yaml -n ${TEST_NS}
# to this step, the pod is created.
oc get pod -n kserve-demo
# NAME READY STATUS RESTARTS AGE
# caikit-tgis-example-isvc-predictor-00001-deployment-dcbfddrk2hv 4/4 Running 0 30m
# 这个pod里面有4个 container
# kserve-container 是真正运行llm的容器,镜像是text-generation-inference,他能看到宿主机上所有的gpu,但是奇怪的是,yaml里面,并没有给他授权,后面再慢慢研究。这个容器,向外暴露了grpc, http服务,但是没有对外声明服务。
# log end with
# Shard 0: Server started at unix:///tmp/text-generation-server-0
# 2023-11-19T13:51:48.465888Z INFO text_generation_launcher: Shard 0 ready in 3.107531075s
# 2023-11-19T13:51:48.565905Z INFO text_generation_launcher: Starting Router
# 2023-11-19T13:51:48.606326Z INFO text_generation_router: Token decoder: Some(Metaspace(Metaspace { replacement: '▁', add_prefix_space: true, str_rep: "▁" }))
# 2023-11-19T13:51:48.615392Z INFO text_generation_router: Connected
# 2023-11-19T13:51:48.615840Z INFO text_generation_router::server: Shard model info: is_seq2seq = true, eos_token_id = 1, use_padding = true
# 2023-11-19T13:51:48.662055Z INFO text_generation_router::grpc_server: gRPC server started on port 8033
# 2023-11-19T13:51:50.663300Z INFO text_generation_router::server: HTTP server started on port 3000
# transformer-container 这个运行了一个caikit-tgis-serving镜像的容器,作用应该是提供grpc服务,然后调用kserve-container,这个容器暴露了user-http服务,并且对外声明了。 并且,这个容器应该是看不到GPU的.
# log end with : "Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)"
# transformer-container的作用,还要再研究一下。
oc get isvc/caikit-tgis-example-isvc -n ${TEST_NS}
# NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE
# caikit-tgis-example-isvc https://caikit-tgis-example-isvc-predictor-kserve-demo.apps.demo-gpu.wzhlab.top True 100 caikit-tgis-example-isvc-predictor-00001 79m
oc get isvc/caikit-tgis-example-isvc -n ${TEST_NS} -o yaml
# apiVersion: serving.kserve.io/v1beta1
# kind: InferenceService
# metadata:
# annotations:
# kubectl.kubernetes.io/last-applied-configuration: |
# {"apiVersion":"serving.kserve.io/v1beta1","kind":"InferenceService","metadata":{"annotations":{"serving.knative.openshift.io/enablePassthrough":"true","sidecar.istio
# .io/inject":"true","sidecar.istio.io/rewriteAppHTTPProbers":"true"},"name":"caikit-tgis-example-isvc","namespace":"kserve-demo"},"spec":{"predictor":{"model":{"modelFormat
# ":{"name":"caikit"},"runtime":"caikit-tgis-runtime","storageUri":"s3://modelmesh-example-models/llm/models/flan-t5-small-caikit"},"serviceAccountName":"sa"}}}
# serving.knative.openshift.io/enablePassthrough: "true"
# sidecar.istio.io/inject: "true"
# sidecar.istio.io/rewriteAppHTTPProbers: "true"
# creationTimestamp: "2023-11-19T13:38:56Z"
# finalizers:
# - inferenceservice.finalizers
# generation: 1
# name: caikit-tgis-example-isvc
# namespace: kserve-demo
# resourceVersion: "5641996"
# uid: 3683461f-0976-4dcd-8ec2-d5eabec6e3af
# spec:
# predictor:
# model:
# modelFormat:
# name: caikit
# name: ""
# resources: {}
# runtime: caikit-tgis-runtime
# storageUri: s3://modelmesh-example-models/llm/models/flan-t5-small-caikit
# serviceAccountName: sa
# status:
# address:
# url: http://caikit-tgis-example-isvc-predictor.kserve-demo.svc.cluster.local
# components:
# predictor:
# address:
# url: http://caikit-tgis-example-isvc-predictor.kserve-demo.svc.cluster.local
# latestCreatedRevision: caikit-tgis-example-isvc-predictor-00001
# latestReadyRevision: caikit-tgis-example-isvc-predictor-00001
# latestRolledoutRevision: caikit-tgis-example-isvc-predictor-00001
# traffic:
# - latestRevision: true
# percent: 100
# revisionName: caikit-tgis-example-isvc-predictor-00001
# url: https://caikit-tgis-example-isvc-predictor-kserve-demo.apps.demo-gpu.wzhlab.top
# conditions:
# - lastTransitionTime: "2023-11-19T13:59:17Z"
# status: "True"
# type: IngressReady
# - lastTransitionTime: "2023-11-19T13:59:16Z"
# severity: Info
# status: "True"
# type: LatestDeploymentReady
# - lastTransitionTime: "2023-11-19T13:59:16Z"
# severity: Info
# status: "True"
# type: PredictorConfigurationReady
# - lastTransitionTime: "2023-11-19T13:59:16Z"
# status: "True"
# type: PredictorReady
# - lastTransitionTime: "2023-11-19T13:59:16Z"
# severity: Info
# status: "True"
# type: PredictorRouteReady
# - lastTransitionTime: "2023-11-19T13:59:17Z"
# status: "True"
# type: Ready
# - lastTransitionTime: "2023-11-19T13:59:16Z"
# severity: Info
# status: "True"
# type: RoutesReady
# modelStatus:
# copies:
# failedCopies: 0
# totalCopies: 1
# states:
# activeModelState: Loaded
# targetModelState: Loaded
# transitionStatus: UpToDate
# observedGeneration: 1
# url: https://caikit-tgis-example-isvc-predictor-kserve-demo.apps.demo-gpu.wzhlab.top
# Perform inference with Remote Procedure Call (gPRC) commands.
oc get ingresses.config/cluster -ojson | grep ingress.operator.openshift.io/default-enable-http2
# empty return
oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=true
# https://github.com/fullstorydev/grpcurl/releases
curl -sSL "https://github.com/fullstorydev/grpcurl/releases/download/v1.8.9/grpcurl_1.8.9_linux_x86_64.tar.gz" | sudo tar -xz -C /usr/local/bin
# export KSVC_HOSTNAME=$(oc get ksvc caikit-tgis-example-isvc-predictor -n ${TEST_NS} -o jsonpath='{.status.url}' | cut -d'/' -f3)
export KSVC_HOSTNAME=$(oc get ksvc caikit-tgis-example-isvc-predictor -n ${TEST_NS} -o jsonpath='{.status.url}')
echo ${KSVC_HOSTNAME}
# grpcurl -vv -insecure -d '{"text": "At what temperature does liquid Nitrogen boil?"}' -H "mm-model-id: flan-t5-small-caikit" ${KSVC_HOSTNAME}:443 caikit.runtime.Nlp.NlpService/TextGenerationTaskPredict
# after do research on https://github.com/caikit/caikit-nlp
# you have to do test like this
# grpcurl do not response.
curl -s --insecure --location --request POST ${KSVC_HOSTNAME}/api/v1/task/text-generation \
--header 'Content-Type: application/json' \
--data "@/dev/stdin" << EOF | jq .
{
"model_id": "flan-t5-small-caikit",
"inputs": "At what temperature does liquid Nitrogen boil?"
}
EOF
# {
# "generated_text": "74 degrees F",
# "generated_tokens": 5,
# "finish_reason": "EOS_TOKEN",
# "producer_id": {
# "name": "Text Generation",
# "version": "0.1.0"
# },
# "input_token_count": 10,
# "seed": null
# }
# curl --insecure --location --request POST http://localhost:8080/api/v1/task/text-generation \
# --header 'Content-Type: application/json' \
# --data "@/dev/stdin"<<EOF
# {
# "model_id": "flan-t5-small-caikit",
# "inputs": "At what temperature does liquid Nitrogen boil?"
# }
# EOF
# 从 kserve-container 和 transformer-container 的日志可以看到,transformer-container 接收了用户请求,然后 kserver-container在算
# log: kserve-container
# 2023-11-20T05:30:27.108752Z INFO text_generation_router::queue: Chose 1 out of 1 requests from buffer, total now 1
# 2023-11-20T05:30:27.108773Z INFO text_generation_router::batcher: New or updated batch #14 of size 1 (10 total toks), max new toks = 20
# 2023-11-20T05:30:27.660363Z INFO text_generation_router::batcher: Prefill took 551.582543ms for 1 inputs, 10 total tokens
# 2023-11-20T05:30:27.739907Z INFO generate:: text_generation_router::grpc_server: Request generated 5 tokens before EosToken, output 12 bytes: "74 degrees F" input=["At what temperature does liquid ..."] prefix_id=None correlation_id="<none>" input_bytes=[46] params=Some(Parameters { method: Greedy, sampling: Some(SamplingParameters { temperature: 0.0, top_k: 0, top_p: 0.0, typical_p: 0.0, seed: None }), stopping: Some(StoppingCriteria { max_new_tokens: 20, min_new_tokens: 0, time_limit_millis: 0, stop_sequences: [], include_stop_sequence: None }), response: Some(ResponseOptions { input_text: false, generated_tokens: true, input_tokens: false, token_logprobs: true, token_ranks: true, top_n_tokens: 0 }), decoding: Some(DecodingParameters { repetition_penalty: 0.0, length_penalty: None }), truncate_input_tokens: 0 }) validation_time=226.987µs queue_t...
# log: transformer-container
# {"channel": "uvicorn.access", "exception": null, "level": "info", "message": "127.0.0.6:0 - \"POST /api/v1/task/text-generation HTTP/1.1\" 200", "num_indent": 0, "thread_id": 140377797240640, "timestamp": "2023-11-20T05:07:20.625607"}
# {"channel": "uvicorn.access", "exception": null, "level": "info", "message": "127.0.0.6:0 - \"POST /api/v1/task/text-generation HTTP/1.1\" 200", "num_indent": 0, "thread_id": 140377797240640, "timestamp": "2023-11-20T05:30:27.742737"}
# try to get api list
curl --insecure -s ${KSVC_HOSTNAME}/openapi.json | jq ' .paths | keys '
# [
# "/api/v1/TextGenerationTaskPeftPromptTuningTrain",
# "/api/v1/TextGenerationTaskTextGenerationTrain",
# "/api/v1/task/server-streaming-text-generation",
# "/api/v1/task/text-classification",
# "/api/v1/task/text-generation",
# "/api/v1/task/token-classification",
# "/health"
# ]
curl -s --insecure --location --request POST ${KSVC_HOSTNAME}/api/v1/task/server-streaming-text-generation \
--header 'Content-Type: application/json' \
--data "@/dev/stdin" << EOF
{
"model_id": "flan-t5-small-caikit",
"inputs": "At what temperature does liquid Nitrogen boil?"
}
EOF
# data: {
# data: "generated_text": "",
# data: "tokens": [],
# data: "details": {
# data: "finish_reason": "NOT_FINISHED",
# data: "generated_tokens": 0,
# data: "seed": 0,
# data: "input_token_count": 10
# data: },
# data: "producer_id": null
# data: }
# data: {
# data: "generated_text": "",
# data: "tokens": [
# data: {
# data: "text": "▁",
# data: "logprob": -1.5990839004516602
# data: }
# data: ],
# data: "details": {
# data: "finish_reason": "NOT_FINISHED",
# data: "generated_tokens": 1,
# data: "seed": 0,
# data: "input_token_count": 0
# data: },
# data: "producer_id": null
# data: }
# data: {
# data: "generated_text": "74",
# data: "tokens": [
# data: {
# data: "text": "74",
# data: "logprob": -3.362251043319702
# data: }
# data: ],
# data: "details": {
# data: "finish_reason": "NOT_FINISHED",
# data: "generated_tokens": 2,
# data: "seed": 0,
# data: "input_token_count": 0
# data: },
# data: "producer_id": null
# data: }
# data: {
# data: "generated_text": " degrees",
# data: "tokens": [
# data: {
# data: "text": "▁degrees",
# data: "logprob": -0.5163507461547852
# data: }
# data: ],
# data: "details": {
# data: "finish_reason": "NOT_FINISHED",
# data: "generated_tokens": 3,
# data: "seed": 0,
# data: "input_token_count": 0
# data: },
# data: "producer_id": null
# data: }
# data: {
# data: "generated_text": " F",
# data: "tokens": [
# data: {
# data: "text": "▁F",
# data: "logprob": -1.1749738454818726
# data: }
# data: ],
# data: "details": {
# data: "finish_reason": "NOT_FINISHED",
# data: "generated_tokens": 4,
# data: "seed": 0,
# data: "input_token_count": 0
# data: },
# data: "producer_id": null
# data: }
# data: {
# data: "generated_text": "",
# data: "tokens": [
# data: {
# data: "text": "</s>",
# data: "logprob": -0.009402398951351643
# data: }
# data: ],
# data: "details": {
# data: "finish_reason": "EOS_TOKEN",
# data: "generated_tokens": 5,
# data: "seed": 0,
# data: "input_token_count": 0
# data: },
# data: "producer_id": null
# data: }
# try grpc call
# change caikit-tgis-servingruntime.yaml port definition to 8085
# and redeploy
# https://github.com/fullstorydev/grpcurl/releases
curl -sSL "https://github.com/fullstorydev/grpcurl/releases/download/v1.8.9/grpcurl_1.8.9_linux_x86_64.tar.gz" | sudo tar -xz -C /usr/local/bin
export KSVC_HOSTNAME=$(oc get ksvc caikit-tgis-example-isvc-predictor -n ${TEST_NS} -o jsonpath='{.status.url}' | cut -d'/' -f3)
echo ${KSVC_HOSTNAME}
# caikit-tgis-example-isvc-predictor-kserve-demo.apps.demo-gpu.wzhlab.top
grpcurl -insecure -vv ${KSVC_HOSTNAME}:443 list
# caikit.runtime.Nlp.NlpService
# caikit.runtime.Nlp.NlpTrainingService
# caikit.runtime.training.TrainingManagement
# grpc.reflection.v1alpha.ServerReflection
# mmesh.ModelRuntime
grpcurl -insecure -vv ${KSVC_HOSTNAME}:443 list caikit.runtime.Nlp.NlpService
# caikit.runtime.Nlp.NlpService.BidiStreamingTokenClassificationTaskPredict
# caikit.runtime.Nlp.NlpService.ServerStreamingTextGenerationTaskPredict
# caikit.runtime.Nlp.NlpService.TextClassificationTaskPredict
# caikit.runtime.Nlp.NlpService.TextGenerationTaskPredict
# caikit.runtime.Nlp.NlpService.TokenClassificationTaskPredict
grpcurl -insecure -d '{"text": "At what temperature does liquid Nitrogen boil?"}' -H "mm-model-id: flan-t5-small-caikit" ${KSVC_HOSTNAME}:443 caikit.runtime.Nlp.NlpService/TextGenerationTaskPredict
# {
# "generated_text": "74 degrees F",
# "generated_tokens": "5",
# "finish_reason": "EOS_TOKEN",
# "producer_id": {
# "name": "Text Generation",
# "version": "0.1.0"
# },
# "input_token_count": "10"
# }
grpcurl -insecure -d '{"text": "At what temperature does liquid Nitrogen boil?"}' -H "mm-model-id: flan-t5-small-caikit" ${KSVC_HOSTNAME}:443 caikit.runtime.Nlp.NlpService/ServerStreamingTextGenerationTaskPredict
# {
# "details": {
# "input_token_count": "10"
# }
# }
# {
# "tokens": [
# {
# "text": "▁",
# "logprob": -1.5947265625
# }
# ],
# "details": {
# "generated_tokens": 1
# }
# }
# {
# "generated_text": "74",
# "tokens": [
# {
# "text": "74",
# "logprob": -3.361328125
# }
# ],
# "details": {
# "generated_tokens": 2
# }
# }
# {
# "generated_text": " degrees",
# "tokens": [
# {
# "text": "▁degrees",
# "logprob": -0.515625
# }
# ],
# "details": {
# "generated_tokens": 3
# }
# }
# {
# "generated_text": " F",
# "tokens": [
# {
# "text": "▁F",
# "logprob": -1.173828125
# }
# ],
# "details": {
# "generated_tokens": 4
# }
# }
# {
# "tokens": [
# {
# "text": "\u003c/s\u003e",
# "logprob": -0.00940704345703125
# }
# ],
# "details": {
# "finish_reason": "EOS_TOKEN",
# "generated_tokens": 5
# }
# }
# Remove the LLM model
oc delete isvc --all -n ${TEST_NS} --force --grace-period=0
oc delete ns ${TEST_NS} ${MINIO_NS}
try using grpc, example
好了,接下来,我们使用caikit+tgis,使用grpc访问,用代码的方式,试一试,做个推理。
- https://github.com/wangzheng422/llm-on-openshift/blob/wzh/examples/notebooks/caikit-basic-query/caikit_grpc_query_example.ipynb
try using langchain, basic
然后,我们使用langchain的方式,访问被caikit-tgis封装的llama2模型。
- https://github.com/wangzheng422/llm-on-openshift/blob/wzh/examples/notebooks/langchain/Langchain-Caikit-Basic.ipynb
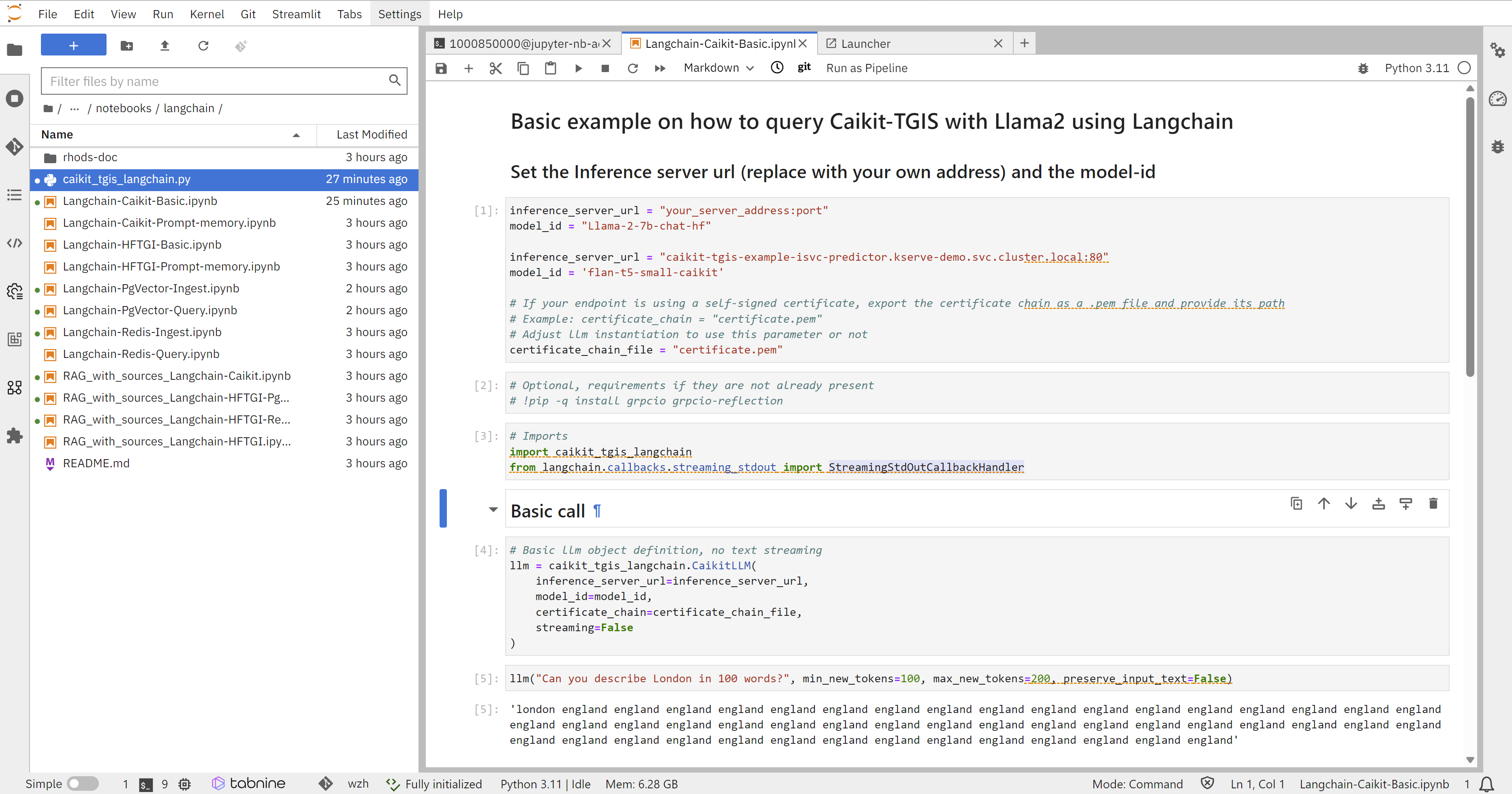
回答效果并不好,因为我们的模型太小了,也正常。
try using langchain, memory
我们使用langchain的方式,访问cailit-tgis封装的llama2,这次我们自定义提示词
- https://github.com/wangzheng422/llm-on-openshift/blob/wzh/examples/notebooks/langchain/Langchain-Caikit-Prompt-memory.ipynb
try using langchain, pgvector, create index
我们使用langchain,想pgvector写入和查询数据。
- https://github.com/wangzheng422/llm-on-openshift/blob/wzh/examples/notebooks/langchain/Langchain-PgVector-Ingest.ipynb
- https://github.com/wangzheng422/llm-on-openshift/blob/wzh/examples/notebooks/langchain/Langchain-PgVector-Query.ipynb
try using langchain, rag, pgvector, langchain
我们使用langchain,实现一个RAG应用,使用pgvector提供向量数据库。
- https://github.com/wangzheng422/llm-on-openshift/blob/wzh/examples/notebooks/langchain/RAG_with_sources_Langchain-Caikit-wzh-pgvector.ipynb
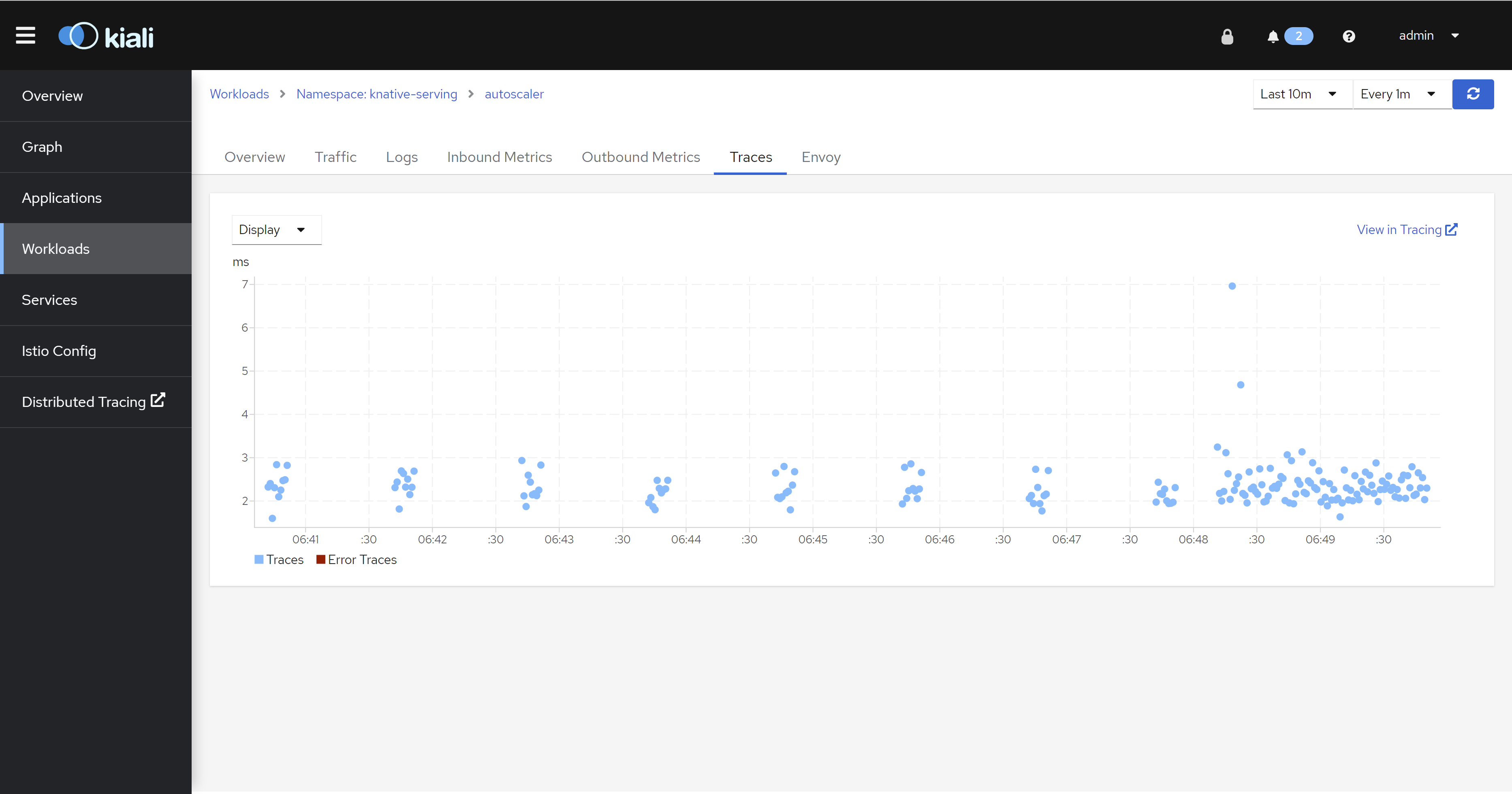
istio
因为我们的架构是serverless,而openshift的serverless又是基于service mesh做的,所以,我们可以从istio上看到很多应用的流量信息。
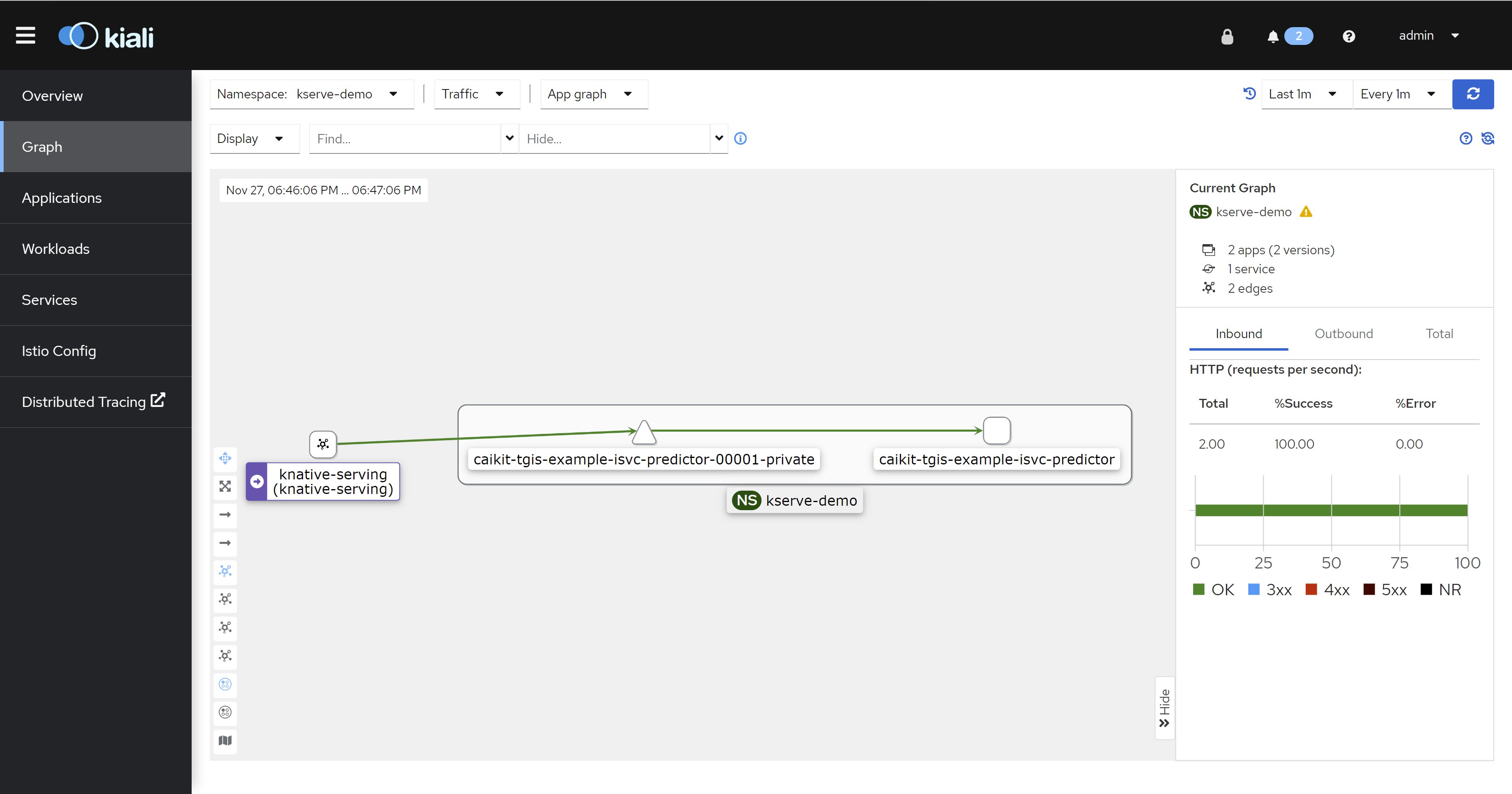
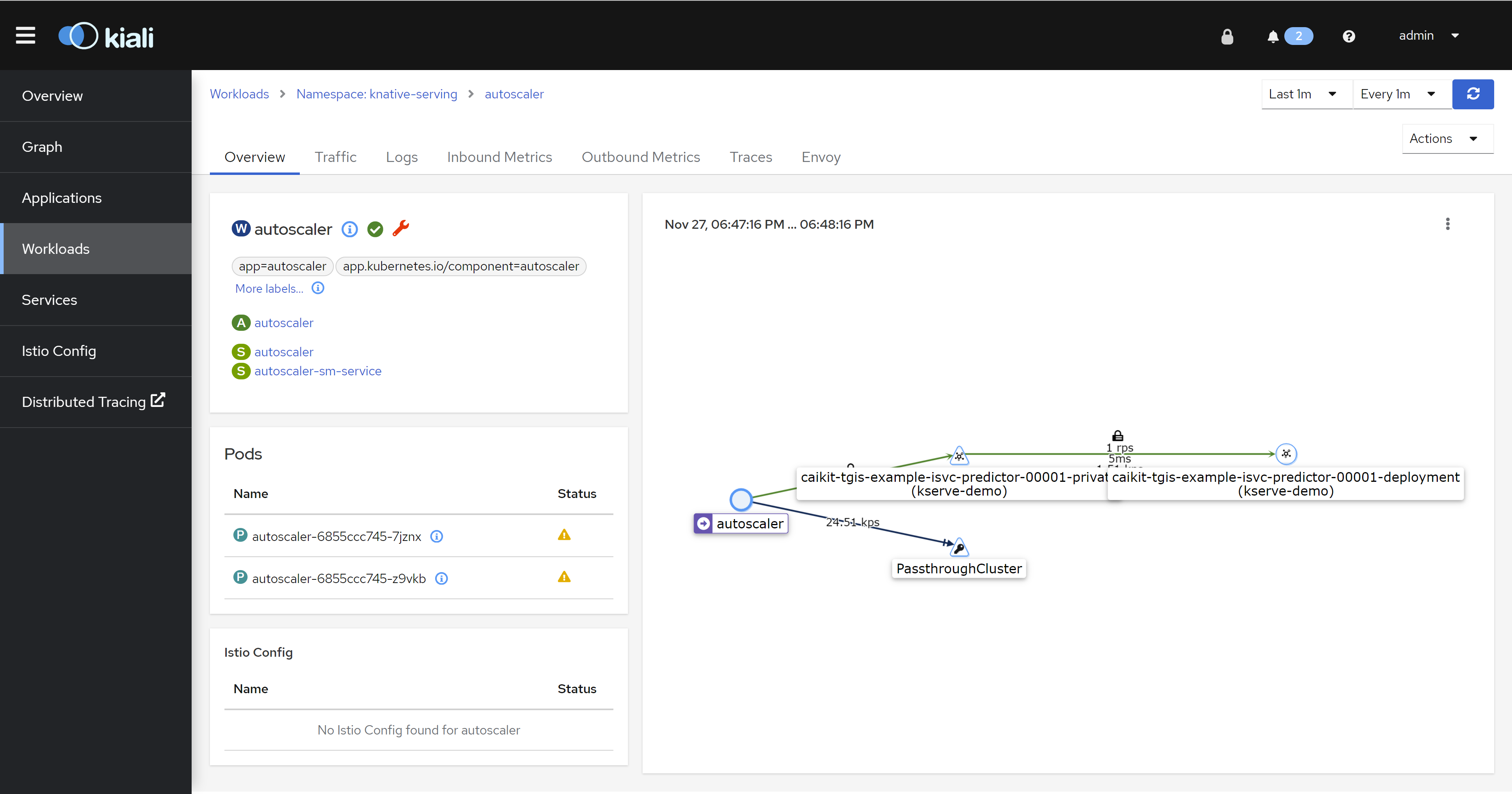
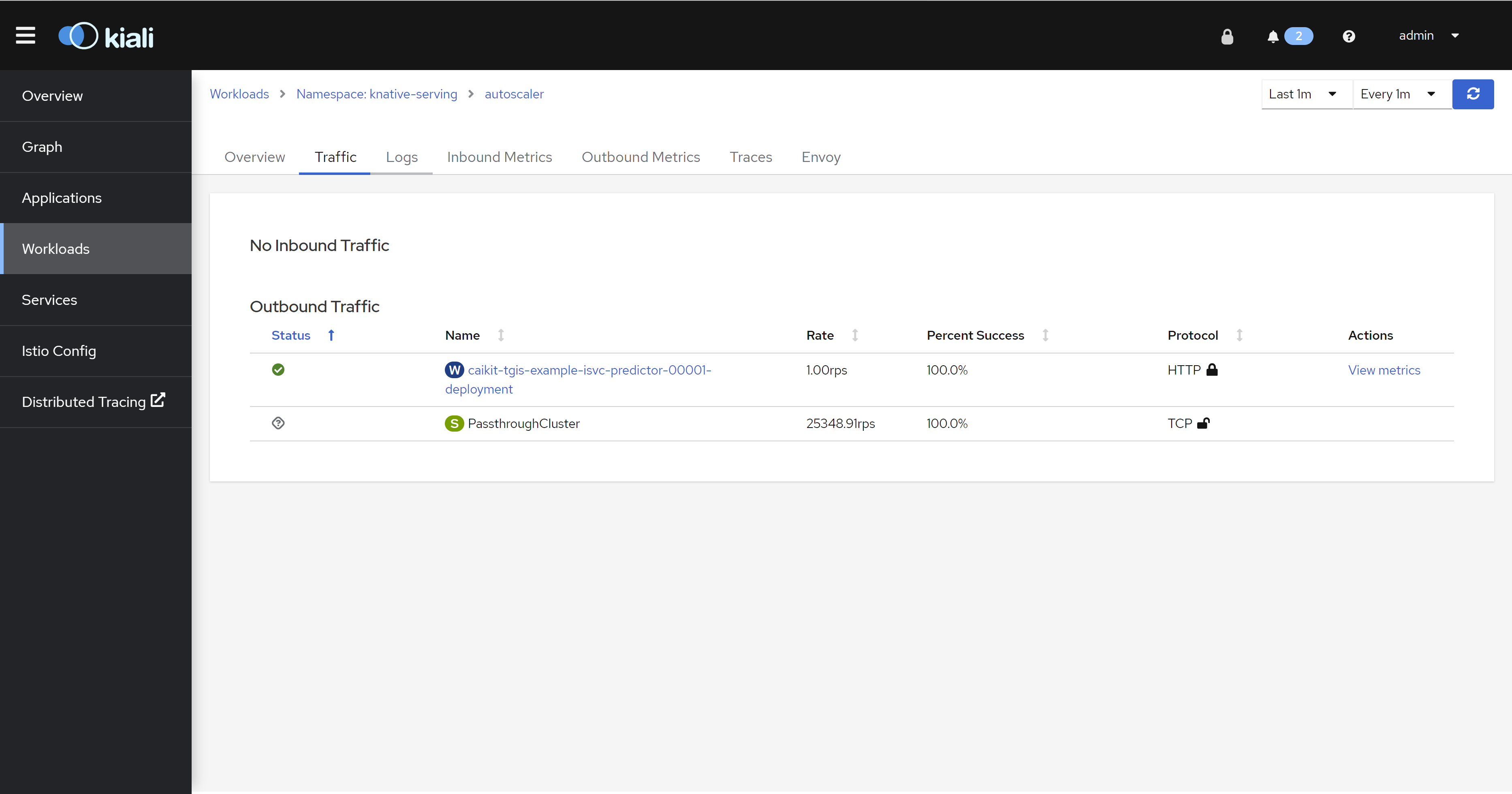
tracing
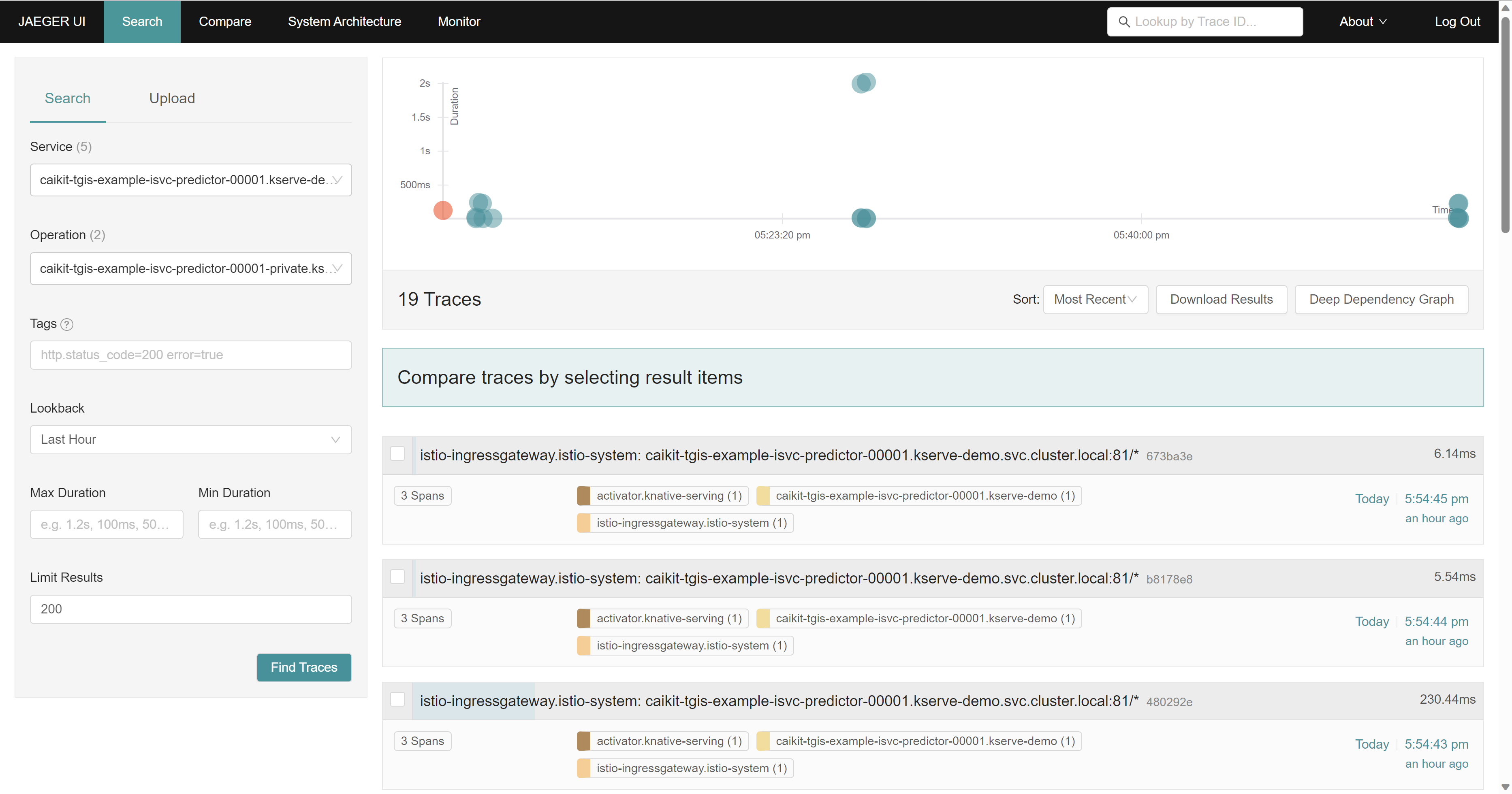
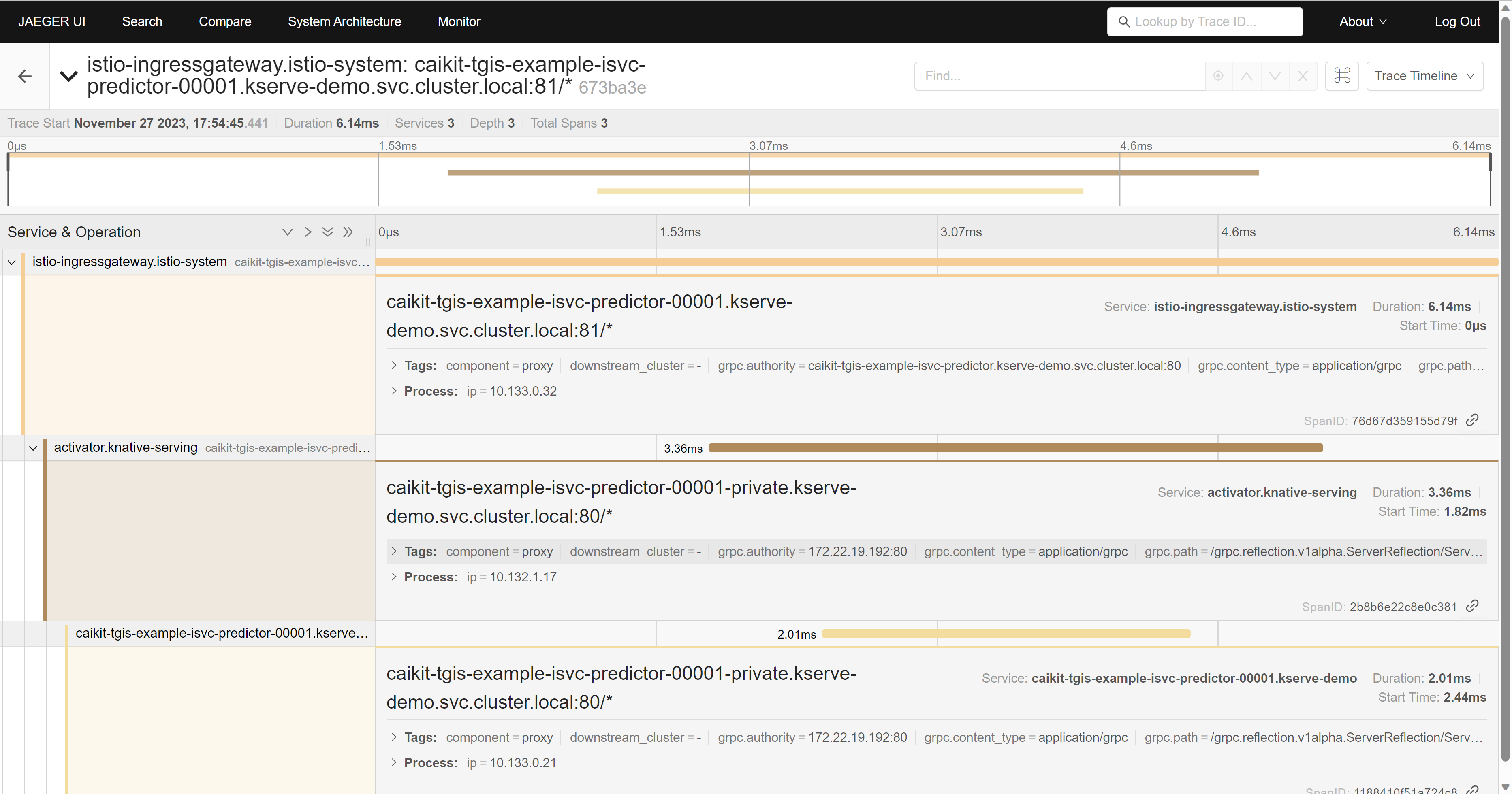
我们也能借助istio的跟踪功能,看到应用的调用链。
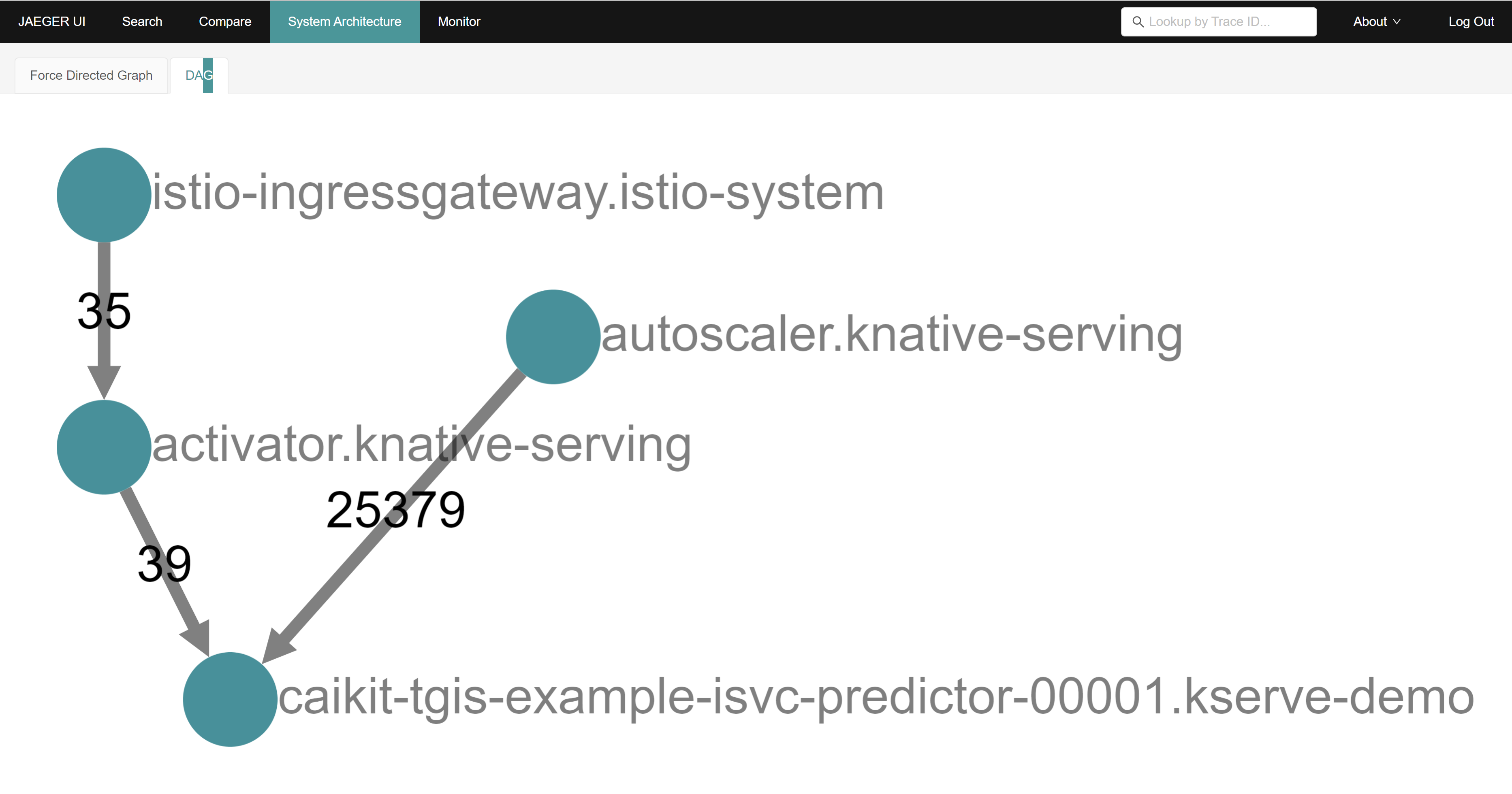
Chatbot+HFTGI+pgvector
上面都是用caikit-tgis作为接口,访问的LLM,接下来,我们使用HFTGI,访问LLM。
try HFTGI basic
- https://github.com/wangzheng422/llm-on-openshift/blob/wzh/examples/notebooks/langchain/Langchain-HFTGI-Basic.ipynb
try HFTGI memory
- https://github.com/wangzheng422/llm-on-openshift/blob/wzh/examples/notebooks/langchain/Langchain-HFTGI-Prompt-memory.ipynb
try HFTGI rag
- https://github.com/wangzheng422/llm-on-openshift/blob/wzh/examples/notebooks/langchain/RAG_with_sources_Langchain-HFTGI.ipynb
try HFTGI pgvector, rag
- https://github.com/wangzheng422/llm-on-openshift/blob/wzh/examples/notebooks/langchain/RAG_with_sources_Langchain-Caikit-wzh-pgvector.ipynb
end
build base container image
# on vultr
mkdir -p /data/nv
cd /data/nv
cat << 'EOF' > nv.Dockerfile
FROM registry.access.redhat.com/ubi9/ubi:9.2
RUN dnf repolist && \
sed -i 's|enabled=1|enabled=0|g' /etc/yum/pluginconf.d/subscription-manager.conf && \
sed -i 's|$releasever|9.2|g' /etc/yum.repos.d/redhat.repo && \
sed -i '/codeready-builder-for-rhel-8-x86_64-rpms/,/\[/ s/enabled = 0/enabled = 1/' /etc/yum.repos.d/redhat.repo && \
dnf -y update && \
dnf install -y --allowerasing coreutils && \
dnf groupinstall -y --allowerasing development server && \
dnf clean all
RUN dnf install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-9.noarch.rpm && \
dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel9/x86_64/cuda-rhel9.repo && \
`#dnf -y module install nvidia-driver:latest-dkms &&` \
dnf -y install --allowerasing cuda && \
dnf install -y --allowerasing libnccl libnccl-devel libnccl-static && \
dnf install -y --allowerasing conda python3.11 && \
dnf clean all
RUN dnf install -y rsync lftp && \
dnf clean all
EOF
podman build --squash -t quay.io/wangzheng422/qimgs:gpu-nv-base-rhel92-v01 -f nv.Dockerfile ./
podman push quay.io/wangzheng422/qimgs:gpu-nv-base-rhel92-v01
podman save quay.io/wangzheng422/qimgs:gpu-nv-base-rhel92-v01 | pigz -c > gpu-nv-base.tgz
python -m http.server 15443
# back to helper node
# copy back the base image
oc image mirror quay.io/wangzheng422/qimgs:gpu-nv-base-rhel92-v01 quaylab.infra.wzhlab.top:5443/wangzheng422/qimgs:gpu-nv-base-rhel92-v01
podman load -i gpu-nv-base.tgz
podman image tag quay.io/wangzheng422/qimgs:gpu-nv-base-rhel92-v01 quaylab.infra.wzhlab.top:5443/wangzheng422/qimgs:gpu-nv-base-rhel92-v01
podman push quaylab.infra.wzhlab.top:5443/wangzheng422/qimgs:gpu-nv-base-rhel92-v01debug pod
# build debug pod
mkdir -p /data/pod
cd /data/pod
cat << EOF > debugpod.dockerfile
FROM docker.io/library/almalinux:9
RUN dnf install -y epel-release && dnf update -y
RUN dnf repolist
RUN dnf install -y --allowerasing which iproute bind-utils wget htop btop bash-completion curl net-tools java-1.8.0-openjdk git iperf3 tcpdump stress-ng fio numactl hwloc-gui lshw nc nmap-ncat dmidecode
RUN dnf clean all -y
RUN curl -sSL "https://github.com/fullstorydev/grpcurl/releases/download/v1.8.9/grpcurl_1.8.9_linux_x86_64.tar.gz" | tar -xz -C /usr/local/bin
EOF
# VAR_IMAGE=quay.io/wangzheng422/debug-pod:alma-9.1
podman build --squash -t quay.io/wangzheng422/debug-pod:alma-9.3 -f debugpod.dockerfile ./
podman push quay.io/wangzheng422/debug-pod:alma-9.3
# on helper node
podman pull quay.io/wangzheng422/debug-pod:alma-9.3
podman tag quay.io/wangzheng422/debug-pod:alma-9.3 quaylab.infra.wzhlab.top:5443/wangzheng422/debug-pod:alma-9.3
podman push quaylab.infra.wzhlab.top:5443/wangzheng422/debug-pod:alma-9.3
label project
oc label ns kserve-demo modelmesh-enabled=true
oc label ns kserve-demo opendatahub.io/dashboard=true